지난 시간 컴퓨터에게 자연어를 이해시키기 위해서,
먼저 우리가 사용하는 문장을 단어라는 단위로 나누어
말뭉치(corpus)에 담는 작업을 했습니다.
이번 시간에는 corpus를 이용해서 단어의 의미를 추출하는 방법을 알아보겠습니다.
다양한 방법이 있지만 이번에는
통계 기반 기법을 이용하려고 합니다.
1. 분산 표현 distributional representation
말이 어렵지만, 간단히 말해 단어를 분산하여 표현한다는 뜻입니다.
예를 들어 '사랑'이라는 단어를 분산 표현으로 나타내면
[0, 0, 1]
[0.21, 0.34, -0.44]
등으로 나타내는 것이죠. 단어를 벡터화시키는 작업이라고도 할 수 있겠습니다.
2. 분포 가설 distributional hypothesis
분산 표현하는 기준은 무엇일까요?
이때는 분포 가설을 따릅니다.
분포 가설은 "단어의 의미는 주변 단어에 의해 형성된다"는 것입니다.
단어 하나하나에는 맥락이 없지만, 단어와 단어가 만나, 문장과 문장이 만나 맥락(context)을 형성하죠.
예를 들어 I drink wine, I drink juice, I drink coffee처럼 drink 다음에는 음료가 등장하기 쉬울 것입니다.
여기서 맥락이란, 특정 단어를 중심에 둔 그 주변 단어를 말합니다.

여기서 window라는 개념이 등장하는데, goodbye를 기준으로 몇 개의 단어를 맥락으로 이용할 지를 결정하는 단위입니다.
여기서는 window 크기가 2이므로 좌, 우 각각 2개씩을 맥락으로 선택합니다.
3. 동시발생 행렬 co-occurrence matrix
분포가설 distribution hypothesis에 입각해, 단어를 벡터로 나타내는 방법을 생각해봅시다
먼저 you의 맥락을 세어보면

오른쪽에는 say가 1개, 왼쪽에는 0개입니다
이를 아래와 같이 표로 나타냅니다.
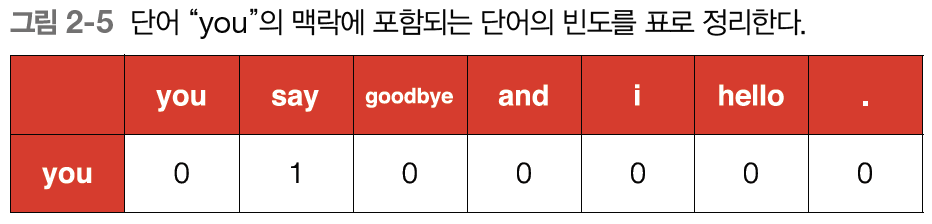
자, 이제는 you라는 단어를 벡터로 표현할 수 있습니다.
you = [0, 1, 0, 0, 0, 0, 0]
마찬가지로 말뭉치를 모두 벡터화시켜 나타내면

이 표의 각 행은 해당 단어를 표현한 벡터가 됩니다.
이를 동시발생 행렬 co-occurrence matrix라고 합니다!
위의 표를 수작업으로 적어보았는데요.
C=np.array([
[0,1,0,0,0,0,0],
[1,0,1,0,1,1,0],
[0,1,0,1,0,0,0],
[0,0,1,0,1,0,0],
[0,1,0,1,0,0,0],
[0,1,0,0,0,0,1],
[0,0,0,0,0,1,0]
])이제 코드로 자동화시켜보겠습니다.
코드를 실행시켜볼까요?
아래의 ▶재생버튼을 누르세요.