Concatenating objects
1. concat()
concate 뜻: 붙이다.
콘켓은 레고를 조합하는 거라고 생각하면 쉽다.
그냥 이어붙인다!
기본 df이다.
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(10, 4))
print(df)
df에서 2개의 다른 데이터프레임을 만든다.
df1 = df[:3]
print(df1)
df2 = df[3:5]
print(df2)

df1, df2를 concat한다.
concat_df= pd.concat([df1, df2])
print(concat_df)
df1, df2가 합쳐져서 나왔다!!
다른 예시도 보자.

df1, df2, df3를 concat한다.
그대로 이어붙인 모습이 된다.

2. keys
데이터를 구분 짓고 싶을 때 쓴다.
axis=0 이 기본값이기 때문에
아래와 같이 세로로 배열된다.
(행렬의 위치인덱스를 생각해보자. axis=0일 때, 행렬에서 첫 번째 요소가 바뀌는 곳이 어디인지를 줄로 이어보자.
그러면 세로가 된다.)
df1> x
df2> y
df3>z
로 key가 생성되어 데이터프레임을 구분지어준다.
keys : sequence, default None. Construct hierarchical index using the passed keys as the outermost level. If multiple levels passed, should contain tuples.

loc[ 값]을 이용하여, y키 값만 뽑아낼 수도 있다.

Set logic on the other axes
위와 똑같은데 이번에는 축만 바꿔서 concat논리를 적용해보자.
axis=1이 되므로 가로로 이어붙어진다.
(행렬에서 변하는 위치인덱스가 열의 값이므로, 변하는 것끼리 이으면 가로가 된다)
1. join='outer'
join='outer'의 의미는
논리연산에서 or의 의미다.
모든 값이라는 뜻이다!

2. joint= 'inner'
join='inner'의 의미는
논리 연산자에서 and의 뜻과 같다.
intersection 즉 교집합인 경우만 이어붙인다.

3. reindex()
만약에 기존 데이터프레임의 index를 그대로 쓰고 싶다면
reindex(데이터프레임.index)라고 쓰면 된다.

Ignoring indexes on the concatenation axis
ignore 무시하다
ignore_index는 인덱스를 무시한다는 뜻이다.
기존 인덱스가 큰 의미를 담고 있지 않을 때 ignoring index를 하면
데이터를 처리할 때 편하다.
ignore_index는 concat의 파라미터로 True/False 불린 값을 갖는다.
만약 True면 기존의 인덱스를 쓰고,
False라면 새롭게 라벨이 되는데 0부터 시작한다.
ignore_index : boolean, default False. If True, do not use the index values on the concatenation axis. The resulting axis will be labeled 0, …, n - 1. This is useful if you are concatenating objects where the concatenation axis does not have meaningful indexing information. Note the index values on the other axes are still respected in the join.

Concatenating with mixed ndims
1. concat>> series +dataframe
series와 dataframe처럼 차원이 다른 것도 concat이 가능하다.

2. 이름이 없다면?
만약 이름이 없는 시리즈가 연속으로 concat된다면,
해당 이름은 연속적인 번호가 된다.
0, 1, 2, 3,,,

3. ignore_index=True

More concatenating with group keys
concat할 때 key가 있는 경우를 보자.
1. 시리즈에 이름이 없다면 자동 생성
s3 시리즈만 foo 이름이 있고, 나머지는 없다면 s4, s5에 자동으로 0, 1로 이름을 만든다.
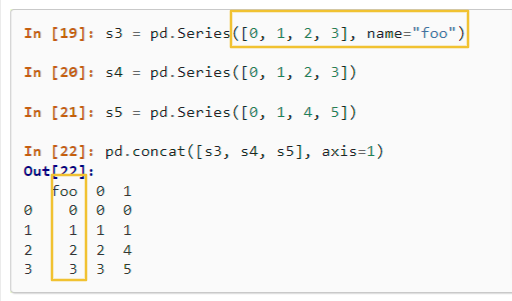
2. 새로운 키로 덮어쓰는 경우
기존에 키가 있었다고 해도, 새로운 키로 overriding, 즉 덮어쓰기 할 수 있다.

3. axis=0 축에서 새로운 key 생성하기
frames는 [df1, df2, df3]이다.
key x, y, z 다음에 있는 숫자들은 index이다.

4. dictionary 딕셔너리 이용하기
dictionary의 key를 keys(x,y,z)로 정하고,
value를 dataframe으로 정해서 concat할 수 있다.

5. 일부 key만 가져오기

Appending rows to a DataFrame
행을 추가할 수 있다.
만약 형식이 맞지 않다면 Transpose(T)를 이용해서 변환한다음
concat하면 된다.

'파이썬 > 판다스' 카테고리의 다른 글
| [판다스 10분 요약 8] join (0) | 2022.09.06 |
|---|---|
| [판다스 10분 요약 7] Merge, how="left", "right", "outer", "inner", "cross" (0) | 2022.09.06 |
| [판다스 10분 요약 5] Operation 연산 (1) | 2022.09.05 |
| [판다스 10분 요약 4] Missing data(NaN, np,nan) 없는 데이터 (1) | 2022.09.05 |
| [판다스 10분 요약 3] Selection 데이터 선택해서 보여주기 (0) | 2022.09.05 |