목차
1. 케라스에서 데이터 가져오기
from keras.datasets import cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()훈련데이터(train)와 실험데이터(test)로 나눈다.

cifar dataset

2. 데이터 전처리
-이미지 크기 정규화하기
이미지는 각 요소가 0~255까지의 값으로 이루어진 픽셀로 구성되어 있다.
이를 255로 나누어서 픽셀값이 0~1 사이의 값이 되도록 정규화한다.
x_train = x_train.astype('float32')/255
x_test = x_test.astype('float32')/255
3. 원핫인코딩하기
레이블은 각 데이터가 갖는 정답이다.
하지만 레이블이 한글이나 영어처럼 되어 있다면, 컴퓨터는 그 뜻을 이해하지 못한다.
따라서 컴퓨터가 이해할 수 있도록 숫자로 변환해야한다.
그 방법 중 하나가 원핫인코딩이다.
하나의 레이블의 길이는 전체 레이블 수이다.
정답인 경우는 1로, 아닌 경우는 0으로 표기한다.
예를 들어, 입력 데이터가 이미지1~이미지3까지 있고.
정답레이블은 사과, 딸기, 배, 복숭아 4개가 있다고 하자.
| 사과 | 딸기 | 배 | 복숭아 | |
| 이미지1 | V | |||
| 이미지2 | V | |||
| 이미지3 | V |
이 값을 원핫인코딩으로 바꿔보면,
V로 체크된 부분은 1로 나머지는 0으로 표시하는 것이다.
| 사과 | 딸기 | 배 | 복숭아 | |
| 이미지1 | 0 | 1 | 0 | 0 |
| 이미지2 | 1 | 0 | 0 | 0 |
| 이미지3 | 0 | 0 | 1 | 0 |
이미지1> 0100
이미지2> 1000
이미지3> 0010
의 값으로 나타낼 수 있다.
케라스는 원핫인코딩 변환 메서드를 제공한다.
import keras
from keras.utils import np_utils
num_classes= len(np.unique(y_train))
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test= keras.utils.to_categorical(y_test, num_classes)
4. 훈련데이터, 검증데이터 분류
하이퍼파라미터가 제대로 작동하는지 검증하기 위해
훈련데이터(train data) 일부를 검증데이터(valid data)로 빼놓는다.
(x_train, x_valid) = x_train[5000:], x_train[:5000]
(y_train, y_valid) = y_train[5000:], y_train[:5000]
5. 훈련데이터, 테스트데이터, 검증데이터의 모양(shape) 확인
print("x_train shape:", x_train.shape)
print("y_train shape:", y_train.shape)
print("x_test shape:", x_test.shape)
print("y_test shape:", y_test.shape)
print("x_valid shape:", x_valid.shape)
print("y_valid shape:", y_valid.shape)>>x_train shape: (45000, 32, 32, 3)
y_train shape: (45000, 10)
x_test shape: (10000, 32, 32, 3)
y_test shape: (10000, 10)
x_valid shape: (5000, 32, 32, 3)
y_valid shape: (5000, 10)
6. 합성곱 신경망 모델링 전 염두 사항
합성곱 신경망에서 모델 구조를 정의하기 전 염두해야 할 사항이다.
1) 층수가 많을 수록 복잡한 문제를 해결할 수 있으나. 계산 복잡도와 오버피팅 가능성은 높아진다.
2) 입력이미지가 신경망 층을 거칠 때마다, 대부분 이미지의 size는 작아지지만 층의 depth는 깊어진다.
3) Conv층>Pooling층 순서로 설계한다. 마지막은 FC층을 설계하여 분류작업의 효율을 높인다.
4) 은닉층의 활성화 함수는 Relu함수를, 마지막 FC층의 활성화 함수는 Softmax함수를 사용한다.
5) FC 전과 후에 dropout층을 설계하여 계산복잡도와 오버피팅 가능성을 낮춘다.
6) 하이퍼파라미터는 여러번의 시행착오를 거치며 감각을 키운다.
7) 기존의 완성된 CNN 모델을 참고한다.
8) 학습할 파라미터의 수 = 필터수 * 필터크기 * 이전 층 출력 깊이 + 편향
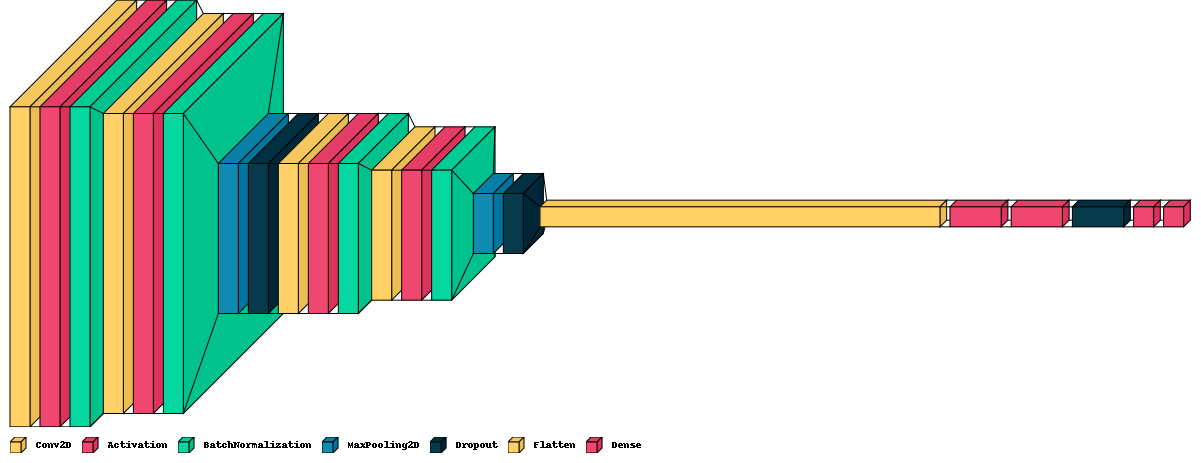
6. 합성곱 신경망 모델링
6-1 케라스에서 모델과 층 import하고 모델 생성하기
from keras.models import Sequential
from keras.layers import Conv2D, MaxPool2D, Flatten, Dense, Dropout
model=Sequential()
6-2 첫 번째 Conv층 쌓기
model=Sequential()
model.add(Conv2D(filters=16, kernel_size=2, padding='same', activation='relu', input_shape=(32,32,3)))
model.add(MaxPool2D(pool_size=2))처음에는 input_shape을 반드시 넣어야 한다.
활성화함수는 relu이다.
풀링층을 넣었다.
학습할 파라미터는 16 * 2 * 2* 3 + 16 = 208개
여기서 3은 입력값에서 나온다.
입력데이터 사이즈는 32,32,3이므로 채널값이 3이다.
입력데이터의 채널값과 필터의 채널값은 같으므로
필터의 사이즈는 2*2*3이라고 볼 수 있다.
풀링층은 학습할 파라미터가 없다.
6-3 두 번째 Conv층 쌓기
model.add(Conv2D(filters=32, kernel_size=2, padding='same', activation='relu'))
model.add(MaxPool2D(pool_size=2))필터의 개수를 32개로 2배 늘렸다. 깊이가 늘어난다.
학습할 파라미터 = 32*2*2*16 +32 = 2080
6-4 세 번째 Conv층 쌓기
model.add(Conv2D(filters=64, kernel_size=2, padding='same', activation='relu'))
model.add(MaxPool2D(pool_size=2))필터의 개수를 64개로 늘렸다.
학습할 파라미터 = 64*2*2*32 +64 = 8256
6-5 드롭아웃 층 쌓기
model.add(Dropout(0.3))
6-6 1차원으로 바꾸기
FC층은 입력값을 1차원으로만 받는다. 따라서 Flatten 함수로 N차원 이미지를 1차원으로 바꿔야 한다.
model.add(Flatten())
6-7 FC 층 쌓기
model.add(Dense(500, activation='relu'))
model.add(Dropout(0.4))
model.add(Dense(10, activation='softmax'))전결합층 다음에 dropout층을 쌓고,
다시 전결합층으로 학습한다.
첫 번째 dense층 학습할 파라미터 = (4*4*64) * 500 + 500 = 512500
두 번째 dense층 학습할 파라미터 = 500*10 +10 = 5010
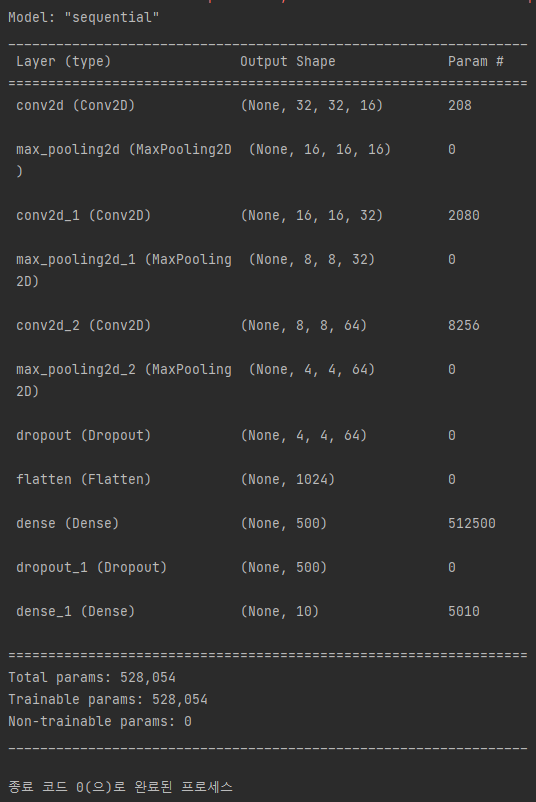
7. 요약
model.summary()요약하면 아래와 같이 나온다.
8. 총 코드
from keras.datasets import cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
import numpy as np
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(20,5))
for i in range(36):
ax = fig.add_subplot(3, 12, i+1, xticks=[], yticks=[])
ax.imshow(np.squeeze(x_train[i]))
x_train = x_train.astype('float32')/255
x_test = x_test.astype('float32')/255
import keras
from keras.utils import np_utils
num_classes= len(np.unique(y_train))
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test= keras.utils.to_categorical(y_test, num_classes)
(x_train, x_valid) = x_train[5000:], x_train[:5000]
(y_train, y_valid) = y_train[5000:], y_train[:5000]
print("x_train shape:", x_train.shape)
print("y_train shape:", y_train.shape)
print("x_test shape:", x_test.shape)
print("y_test shape:", y_test.shape)
print("x_valid shape:", x_valid.shape)
print("y_valid shape:", y_valid.shape)
from keras.models import Sequential
from keras.layers import Conv2D, MaxPool2D, Flatten, Dense, Dropout
model=Sequential()
model.add(Conv2D(filters=16, kernel_size=2, padding='same', activation='relu', input_shape=(32,32,3)))
model.add(MaxPool2D(pool_size=2))
model.add(Conv2D(filters=32, kernel_size=2, padding='same', activation='relu'))
model.add(MaxPool2D(pool_size=2))
model.add(Conv2D(filters=64, kernel_size=2, padding='same', activation='relu'))
model.add(MaxPool2D(pool_size=2))
model.add(Dropout(0.3))
model.add(Flatten())
model.add(Dense(500, activation='relu'))
model.add(Dropout(0.4))
model.add(Dense(10, activation='softmax'))
model.summary()다음 시간에는 모델 컴파일 후 학습, 평가해보도록 한다.
'머신러닝 > CNN' 카테고리의 다른 글
| cifar10 데이터 이용한 CNN 모델 설계 2 (0) | 2023.04.15 |
|---|---|
| 컴퓨터 비전 시스템의 이해 (0) | 2023.04.15 |