map
map은 파이썬 내장함수이다.
각 시퀀스의 각 요소에 ()안의 함수를 적용하여 새로운 시퀀스를 생성한다.
이 함수는 주로 list, tuple 등 iterable한 객체에 사용된다.
# 예시 1: 리스트 요소 제곱하기
numbers = [1, 2, 3, 4, 5]
squared_numbers = list(map(lambda x: x**2, numbers))
print(squared_numbers)
# 출력: [1, 4, 9, 16, 25]
# 예시 2: 문자열 길이 구하기
fruits = ["apple", "banana", "cherry"]
lengths = list(map(len, fruits))
print(lengths)
# 출력: [5, 6, 6]
pandas로 dataframe을 만들고, cores 속성 값 중, 길이가 1인 것을 찾아보려고 한다.

data['cores'].map(len)==1187개의 row 중 len가 1인 것은 true로 반환되고, 아닌 것은 false로 반환된다.
false인 것의 개수를 알고 싶다면 sum함수를 더한다.
count= sum(data['cores'].map(len)!=1)
print(count)>>3
원래의 data에서, 길이가 1인 것들만 extract하고 싶다면 불린형을 데이터프레임에 넣으면 된다.
그러면 3개의 row가 remove된다.
data=data[data["cores"].map(len)==1]
data.count() #3개가 제외된 184개가 된다.
lambda
람다 함수는 파이썬에서 간단한 익명 함수를 정의할 때 사용되는 함수이다.
익명 함수란 이름이 없는 함수로, 일회성으로 사용될 때 간편하고 심플하게 쓸 수 있어 유용하다.
간결한 문법으로 표현되며 iterable한 경우 쓰는 map(), filter()과 함께 사용된다.
# 예시 1: 인자 x를 받아 x의 제곱을 반환하는 람다 함수
square = lambda x: x**2
print(square(5))
# 출력: 25
# 예시 2: 두 인자 x와 y를 받아 더한 값을 반환하는 람다 함수
add = lambda x, y: x + y
print(add(3, 4))
# 출력: 7
# 예시 3: 리스트의 각 요소에 대해 제곱 연산을 수행하는 람다 함수와 map() 함수 사용
numbers = [1, 2, 3, 4, 5]
squared_numbers = list(map(lambda x: x**2, numbers))
print(squared_numbers)
# 출력: [1, 4, 9, 16, 25]lambda 키워드를 적는다.
: 콜론을 기준으로 왼쪽에는 입력 인자를 오른쪽에는 반환값을 넣는다.
filter
필터는 거른다는 의미를 갖는다.
원래의 원소들 중 조건에 맞는 원소만 걸러 새로운 리스트를 반환해낸다.
filter함수는 첫 번째 인자로 조건을 확인하는 함수를, 두 번째 인자로 대상 리스트나 iterable한 객체를 받는다.
필터 함수를 거치면 조건을 만족하는 새로운 리스트가 return 된다.
# 예시 1: 짝수인 요소들로 이루어진 리스트 생성
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
even_numbers = list(filter(lambda x: x % 2 == 0, numbers))
print(even_numbers)
# 출력: [2, 4, 6, 8, 10]
# 예시 2: 길이가 5인 문자열로 이루어진 리스트 생성
fruits = ["apple", "banana", "cherry", "orange", "kiwi"]
length_5 = list(filter(lambda x: len(x) == 5, fruits))
print(length_5)
# 출력: ["apple", "kiwi"]
to_datetime()
pandas 라이브러리 함수로 데이터프레임의 열에 있는 날짜, 시간 정보를 처리하고 조직하는데 유용하다.
pandas의 datetime 형식으로 변환해야 pandas에서 처리하기 쉽기 때문에,
다양한 형식으로 저장되어 있는 날짜, 시간 정보를 to_datetime() 함수로 변환하기를 바란다.
import pandas as pd
datetime_str = '2021-09-30 15:30:00'
datetime_obj = pd.to_datetime(datetime_str)
datetime_obj
#Timestamp('2021-09-30 15:30:00')예를 들어 위의 datetime_str은 겉보기에는 날짜, 시간 형식이지만 str 형태이다.
따라서 pd.to_datetime()을 이용해 판다스의 timestamp 속성으로 바꿀 수 있다.
다른 예를 보자.
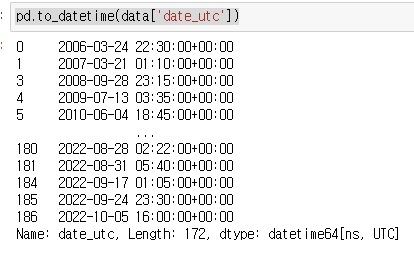
아래의 데이터 프레임의 date_utc의 속성 값은 날짜, 시간으로 되어 있다. 하지만 pandas의 형식이 아니기 때문에 자료를 처리, 조직하는데 불편하다. 따라서 to_datetime()으로 형식을 변환해보자.
pd.to_datetime(data['date_utc'])
date()
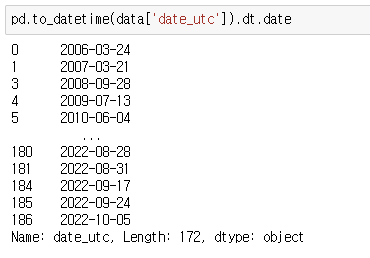
판다스의 datatime 객체에서 날짜 정보를 추출하기 위해서는 'date() 매서드를 사용한다.
import pandas as pd
datetime_obj = pd.to_datetime('2023-05-28 09:30:00')
date_only = datetime_obj.date()
print(date_only)
#2023-05-28
datetime.date(2023, 5, 23)
datetime.date(연.월.일)은 파이썬의 내장 datetime 모듈의 date 클래스를 사용하여 날짜 정보를 나타내는 객체를 생성하는 코드이다.
시간 정보는 없고 날짜 코드만 다룬다.
import datetime
date_obj = datetime.date(year, month, day)
dt
판다스에서 datatime 객체에 접근하기 위한 속성이다. 접근자라 불리기도 한다.
예를 들어 pandas datetime 객체에서 year, month, day 등과 같은 속성에 접근할 때는
.dt.year, .dt.month, .dt.day와 같이 사용된다.
pd.to_datetime(data['date_utc']).dt.year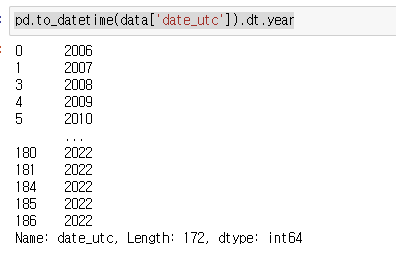
'Certificate > data science-IBM' 카테고리의 다른 글
| webscrapping, beautifulsoup, getText, get, strip, isdigit, fromkeys, extract (0) | 2023.05.29 |
|---|---|
| loc, iloc, isnull, dropna, fillna, astype, dtype (0) | 2023.05.28 |
| data visualization, dashboard, plotly기초 (0) | 2023.05.23 |
| data methodololy, CRISP-DM, 데이터분석 단계 (0) | 2023.05.22 |
| dashboard (0) | 2023.05.11 |