1. 판다스 불러오기
import pandas as pdas 뒤에는 별명이 온다고 생각하면 된다.
내가 부르고 싶은 별명을 적으면 되는데,
대체로 pandas는 pd라고 한다.
2. 넘파이
import numpy as np팥빵에서 팥과 빵이 분리될 수 없듯,
판다스와 넘파이의 관계도 그렇다.
넘파이는 숫자들의 배열을 도와주는 라이브러리로,
데이터처리를 할 때 꼭 필요하다.
3. Series
판다스에서 Series는 파이썬에서 list라고 생각하면 된다.
데이터를 나열해 놓은 묶음이라고 생각하면 된다.
Series 시리즈를 만들어보자.
import pandas as pd
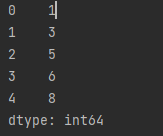
create_series = pd.Series([1,3,5,6,8])
print(create_series)이전에 배웠던 객체 개념을 생각해보자.
pd라는 라이브러리 안에 있는 속성, 메소드 중
Series 메소드를 사용해서 [1,3,5,6,8] 데이터를
판다스가
보기 좋게 시각화해주는 거다.
4. 데이터프레임 DataFrame
이번에는 시리즈를 넘어, 데이터프레임을 만들어볼 거다.
Frame의 뜻은 틀을 이야기한다.
액자 틀만 생각해도
프레임은 대체로 사각형 형태라는 것을 짐작할 수 있다.
DataFrame은 데이터를 모아 만드는데, 전체적으로 사각형 모양이다.
DataFrame에 데이터를 넣으려면,
우후죽순으로 넣는 것이 아니라
특정 열, 행에 의미를 담아 넣어야 한다.
즉, DataFrame을 만드는데 필요한 구성요소는
열, 행, 인덱스이다.
1) 인덱스
date_range(시작날짜, 기간)
dates = pd.date_range("20220905", periods=3)
print(dates)
DatetimeIndex(['2022-09-05', '2022-09-06', '2022-09-07'], dtype='datetime64[ns]', freq='D')
2) 열
columns = list("ABCD")
print(columns)['A', 'B', 'C', 'D']
3) 행
random.randn(a, b)
정규분포를 따르는 무작위 수를 a X b 수만큼 생성한다.
row = np.random.randn(3,4)
print(row)[[ 0.24888736 0.3814019 1.11922495 1.58110036]
[ 0.66700659 1.08609808 -0.04402899 -0.85944855]
[-1.33311626 -0.19338979 1.23554298 0.0939357 ]]
여기까지 인덱스, 열, 행을 모두 만들었으니
본격적으로 데이터프레임을 만들어본다.
1 + 2 + 3 =
4) pandas.DataFrame(행, 인덱스, 열)
dataframe = pd.DataFrame(row, index = dates, columns= columns)
print(dataframe)
5) 딕셔너리--> 데이터프레임
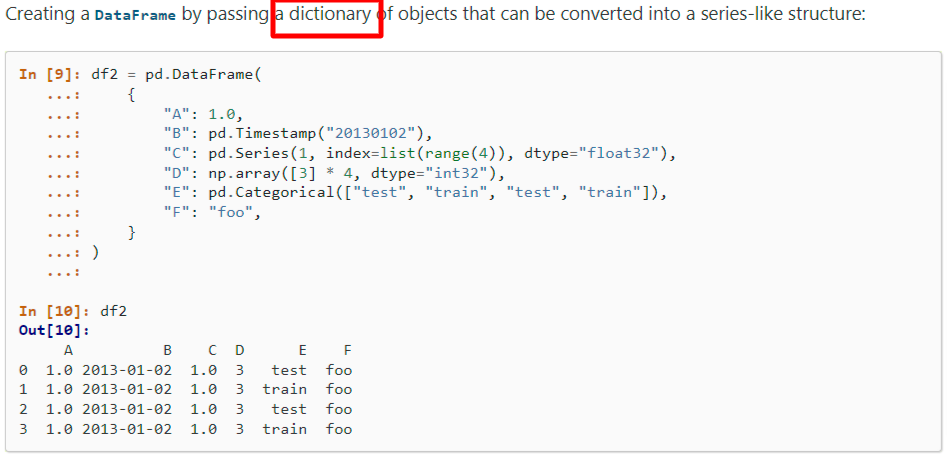
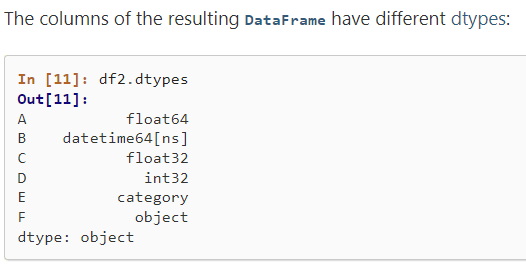
A, B, C, D, E, F 가 가지고 있는 데이터들의 데이터타입은 모두 다르다.
'파이썬 > 판다스' 카테고리의 다른 글
| [판다스 10분 요약 6] Concat 데이터 합치기 (0) | 2022.09.06 |
|---|---|
| [판다스 10분 요약 5] Operation 연산 (1) | 2022.09.05 |
| [판다스 10분 요약 4] Missing data(NaN, np,nan) 없는 데이터 (1) | 2022.09.05 |
| [판다스 10분 요약 3] Selection 데이터 선택해서 보여주기 (0) | 2022.09.05 |
| [판다스 10분 요약 2] Viewing data 데이터 보기 (0) | 2022.09.05 |