목차
1. model evaluation
in-sample evaluation tells us how well our model will fit the data used to train it.
problem is that it's not sure how well the trained model can be worked to predict new data.
Therefore we should make data splited, two ways in-sample data(training data) and out-of sample data(test set).
training/testing sets
train_test_split()
x_train1, x_test1, y_train1, y_test1 = train_test_split(x_data, y_data, test_size=0.4, random_state=0)
print("number of test samples :", x_test1.shape[0])
print("number of training samples:",x_train1.shape[0])cross_val_score()
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LinearRegression
lre=LinearRegression()
Rcross = cross_val_score(lre, x_data[['horsepower']], y_data, cv=4)
print("The mean of the folds are", Rcross.mean(), "and the standard deviation is" , Rcross.std())
from sklearn.model_selection import cross_val_predict
yhat = cross_val_predict(lre,x_data[['horsepower']], y_data,cv=4)
yhat[0:5]
2. generalization
Generalization error란 모델이 처음 보는 새로운 데이터에 대해 얼마나 잘 예측할 수 있는지를 나타내는 지표입니다. 모델이 훈련 데이터에만 과도하게 적합되어 일반적인 패턴을 파악하지 못하면, 새로운 데이터에 대한 예측 성능이 떨어지게 됩니다. 따라서 모델의 일반화 성능을 향상시키는 것이 중요합니다.
3. cross validation 교차검증
데이터 셋을 분할하여 모델 학습과 평가를 반복하는 방법으로 일반화 성능을 정확하게 평가하는 방법
가장 일반적인 교차 검증 방법은 k-fold 교차 검증입니다. 이 방법은 데이터 셋을 k개의 부분 집합으로 나누고, 각각의 부분 집합에서 한 번씩 검증 셋으로 사용하며, 나머지 k-1개 부분 집합을 훈련 셋으로 사용하여 모델을 학습합니다. 이렇게 k번 반복하여 각각의 검증 성능을 평균하여 최종적인 모델 성능을 평가합니다.
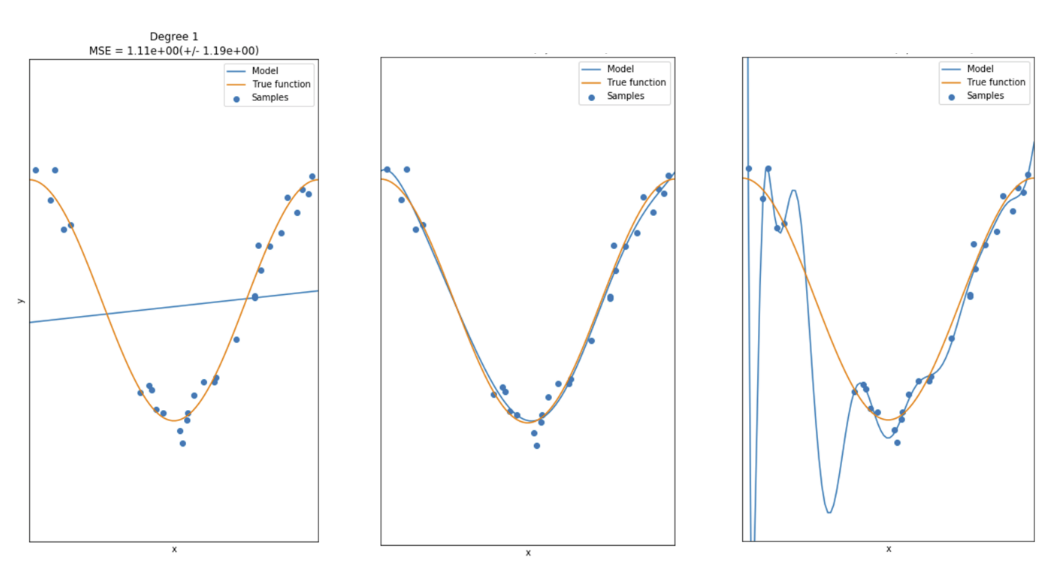
4. overfitting, underffiting, good model
5. Ridge Regression
Ridge Regression은 선형 회귀 모델에 L2 규제를 추가하여 모델의 복잡도를 제한하는 방법입니다. L2 규제는 가중치(w)의 제곱합을 최소화하는 방향으로 모델을 학습합니다. 이를 통해 일반화 성능을 높이고, overfitting을 방지할 수 있습니다.
Ridge Regression에서는 추가적인 하이퍼파라미터인 alpha 값을 지정해야 합니다. alpha 값이 커질수록 규제 강도가 증가하여 가중치(w)의 크기를 더 많이 줄이고 모델의 복잡도를 낮춥니다. 반대로, alpha 값이 작아질수록 규제 강도가 낮아져 가중치(w)의 크기를 줄이지 않거나 증가시킬 수 있으며, 모델의 복잡도가 높아질 수 있습니다.
alpha 값은 모델의 일반화 성능에 영향을 미치므로, 적절한 값을 찾기 위해 교차 검증을 수행하는 것이 좋습니다.
from sklearn.linear_model import Ridge
RidgeModel=Ridge(alpha=0.1)
RidgeModel.fit(x_train, y_train)
RidgeModel.score(x_train, y_train)
6. Grid search
scikit learn has a means of automatically iterating over these hyperparameters using cross-validation called grid search.
Grid search는 모델의 hyperparameter를 조정하는 방법 중 하나입니다. Grid search는 가능한 모든 hyperparameter 조합에 대해 모델을 학습하고 검증하는 방법입니다. 즉, 각 hyperparameter마다 가능한 모든 값을 나열한 그리드를 만들고, 이 그리드를 모두 탐색하여 최적의 조합을 찾습니다. Grid search를 사용하면 모델의 최적 hyperparameter를 찾을 수 있지만, hyperparameter의 조합이 많아질수록 계산 시간이 증가하기 때문에, 모든 hyperparameter 조합을 탐색하는 것이 현실적으로 불가능할 수도 있습니다. 이 경우, Randomized search와 같은 다른 hyperparameter 탐색 방법을 고려할 수 있습니다.
from sklearn.model_selection import GridSearchCV
parameters1= [{'alpha': [0.001,0.1,1, 10, 100, 1000, 10000, 100000, 100000]}]
parameters1
RR=Ridge()
Grid1 = GridSearchCV(RR, parameters1,cv=4)
Grid1.fit(x_data[['horsepower', 'curb-weight', 'engine-size', 'highway-mpg']], y_data)
BestRR=Grid1.best_estimator_
BestRR.score(x_test[['horsepower', 'curb-weight', 'engine-size', 'highway-mpg']], y_test)
7. polynomialFeature
we can perform a polynomial transform on multiple features.
from sklearn.preprocessing import PolynomialFeatures
pr=PolynomialFeatures(degree=2)
x_train_pr=pr.fit_transform(x_train)
x_test_pr=pr.fit_transform(x_test)
from sklearn.linear_model import Ridge
RidgeModel2=Ridge(alpha=0.1)
RidgeModel2.fit(x_train_pr, y_train)
RidgeModel2.score(x_train_pr, y_train)