목차
마이크로소프트 학습
https://learn.microsoft.com/ko-kr/training/
학습
경력을 발전시키고 최고의 위치에서 입지를 다지는 데 필요한 기술은 쉽게 얻을 수 있는 것이 아닙니다. 여기 빠른 목표 달성에 도움이되는 실습 교육에 대한 성과 보답형 방식이 있습니다. 포
learn.microsoft.com
★ 학습> 제품> Azure> Microsoft Azure AI 기본 사항: 기계학습을 위한 시각적 도구 살펴보기


★ 개념학습을 한다.
ex) 회귀분석
yhat 예측값

Microsoft Machine Learning Studio (classic)
Module Reference Complete reference of all modules you can insert into your experiment and scoring workflow
studio.azureml.net
2024년 6월 이후부터는 아래의 사이트에서 가능하다.
https://azure.microsoft.com/ko-kr/products/machine-learning/
직접 데이터셋을 선택하여, preprocessing을 거쳐 인공지능 모델에 적용해보자.
주의할 점은, 각각의 단계에서 run을 진행해야 그 다음 단계로 넘어갈 수 있다는 것이다.
<사전단계>
New 버튼 클릭(왼쪽 하단)

데이터는 샘플에 있는 automobile price.
이름바꾸기
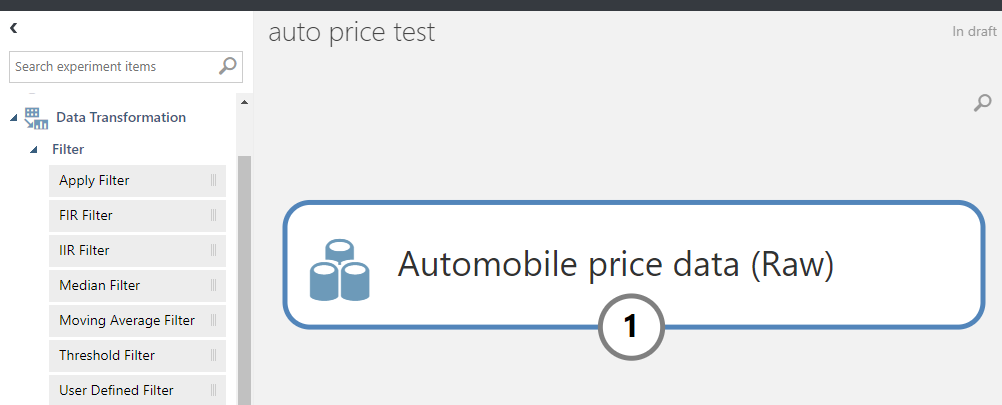
1. Data PreProcessing
★ 데이터 살펴보기


★ select columns in dataset> 데이터 연결 > 칼럼 선택


★ run> clean missing data> 전체컬럼 선택
null값 제거한다.

★ Normalize Data> method:MinMax
0~1사이의 값으로 스케일 통일


★ Price는 레이블이기 때문에 제외하고 스케일링한다.

2. Split data
★ Split Data>
Fraction 어떤 비율로 할건지 정한다. 0.7 이라면 전체의 70프로를 train 데이터
random seed 시드를 정하면 실행할 때마다 동일한 데이터 셋이 된다. 없다면 랜덤.
1, 2,번 데이터로 나뉘는데
1번은 train 데이터
2번은 test 데이터

3. Model
★ Linear Regression > Train model > 연결하기
train model에서 column은 price를 선택


4. Score
★ Score Model>
해당 train model이 split data의 test data를 집어 넣었을 때, 얼마나 잘 작동하는 가를 점수 메겨본다.


5. Evaluate
★ Evaluated Model>
해당 model이 스탠다드한 관점에서 얼마나 잘 만들어졌는지를 평가


인공지능 모델을 다른 것을 선택해서 결과를 비교해보자.


★ webservice 올리기

★ raw data delete
(keyboard delete버튼 누름)
★ Enter Data Manually
데이터를 수동으로 넣기
symboling,normalized-losses,make,fuel-type,aspiration,num-of-doors,body-style,drive-wheels,engine-location,wheel-base,length,width,height,curb-weight,engine-type,num-of-cylinders,engine-size,fuel-system,bore,stroke,compression-ratio,horsepower,peak-rpm,city-mpg,highway-mpg
3,NaN,alfa-romero,gas,std,two,convertible,rwd,front,88.6,168.8,64.1,48.8,2548,dohc,four,130,mpfi,3.47,2.68,9,111,5000,21,27
3,NaN,alfa-romero,gas,std,two,convertible,rwd,front,88.6,168.8,64.1,48.8,2548,dohc,four,130,mpfi,3.47,2.68,9,111,5000,21,27
1,NaN,alfa-romero,gas,std,two,hatchback,rwd,front,94.5,171.2,65.5,52.4,2823,ohcv,six,152,mpfi,2.68,3.47,9,154,5000,19,26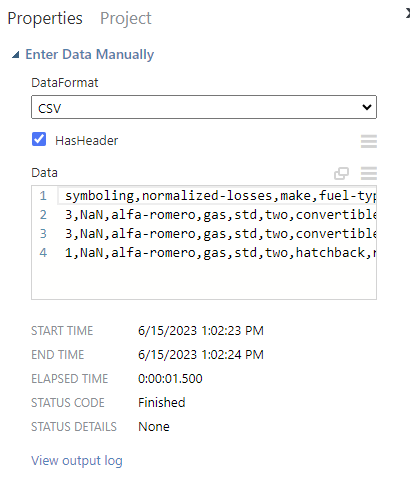

★ selected columns in datasets 에 에러 처리 - price
또한 지난 시간 data preprocessing에서 null값 처리할 때, price도 포함하여 처리했으므로
원래 모델에서 cleansing data에서 selected column값 중 price 삭제
★ deploy web service

★ General 클릭

★ test

★ Consume> Python 3 +

jupyter notebook 실행하기
- data 넣고, API 키 넣고 실행하기
'마이크로소프트 > Azure' 카테고리의 다른 글
| [azure] computer vision, custom vision (0) | 2023.06.15 |
|---|---|
| [Azure] 군집 실습하기 - K-means clustering (0) | 2023.06.15 |
| [Azure] 분류 실습하기- logistic regression (0) | 2023.06.15 |
| [Azure] 분류 모델 평가지표 confusion metrics, Recall, sensitivity, Precision, TPR, FPR, Specificity, roc curve, F1 score (0) | 2023.06.15 |
| [Azure] AI-900, 인공지능 개요, azure (0) | 2023.06.14 |