이번에는 빅분기 시험 공부, ADP 시험 준비 하며 필수적인 pandas 공부 요약 정리해보도록 한다.
목차
# pandas 라이브러리
import pandas as pd
import numpy as np
# 시각화 라이브러리
import matplotlib.pyplot as plt
import seaborn as sns
# 행 /열 최대로 보기
pd.set_option('display.max_rows',None)
pd.set_option('display.max_columns', None)
# 경고 무시
import warnings
warnings.filterwarnings("ignore")
0. 외부파일
불러오기
1) csv
pd.read_csv(" 이름.csv", header=?, index_col= ?)
index_col 이용해서, 특정열을 인덱스로 지정할 수 있음
2) excel
pd.read_excel("이름.xlsx", sheet_name=? , header= ?, index_col=None)
sheet_name 설정 가능
header 설정 가능
index_col = None 인덱스 생성 안함(기본값)
index_col = 1 ( 1번째 컬럼을 인덱스로 생성)
pd.read_excel("/content/final(11.10).xlsx", index_col=0)
3) json
pd.read_json(" .json")
저장하기
데이터이름.to_csv(".csv", index = ? , encoding=?)
- 인코딩
utf-8-sig : UTF-8 인코딩에 BOM이 추가된 형식으로 윈도우와 엑셀 같은 프로그램과의 호환성을 위해 사용함
index : True/ False 기존 인덱스 가져갈지 말지 결정
df4.to_excel("/content/final(11.10).xlsx")
1. Series
판다스에서 시리즈는 파이썬의 list와 같이, 데이터를 나열해 놓은 묶음이다.
pandas는 Series 메소드를 사용해서 [1.2.3.4.5] 데이터를 보기 좋게 시각화 해준다.
create_seriese= pd.Series([1,2,3,4,5])
2. DataFrame
Frame은 사각형을 말한다. Series는 단순한 1차원이었다면, Frame은 2차원 이상의 차원이다.
DataFrame에 데이터를 넣을 때는 특정 열, 행, 인덱스에 의미를 담아 넣는다.
< 데이터 만들기 >
1) list()
Columns= list('ABCD") -> ['A', 'B', 'C', 'D']
2) date_range(시작날짜, 기간)
dates = pd.date_range("20220905", periods=3)->DatetimeIndex(['2022-09-05', '2022-09-06', '2022-09-07'], dtype='datetime64[ns]', freq='D')
3) random.randn(a, b)
정규분포를 따르는 무작위 수를 a*b차원 만큼 생성
< 데이터프레임 만들기 >
1) pandas.DataFrame(행, 인덱스, 열)
dataframe = pd.DataFrame(row, index = dates, columns= columns)
2) Dictionary -> DataFrame

3. 데이터보기
1) head() / tail()
앞/뒤 5개의 행만 보여준다.
( ) 안에 숫자를 넣으면 원하는 개수만큼 볼 수 있다.
head(10), tail(3) 등

2) index, columns
DataFrame의 index와 columns를 보여준다.

3) shape
DataFrame.shape
(Row, Column) 차원을 보여줌
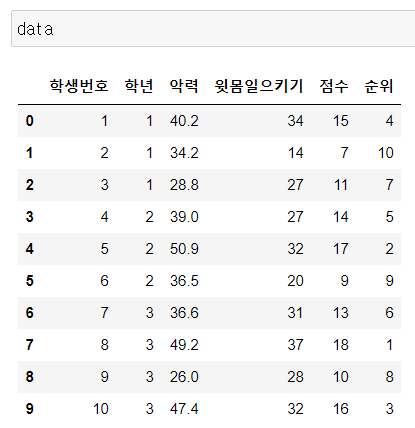
(10,6)
4) info()
기본 정보
클래스 유형
행인덱스 개수
열 이름, 개수, 널값, 타입
memory

5) dtypes
자료형 확인
series, dataframe 가능
원소 불가능 -- > type(원소)
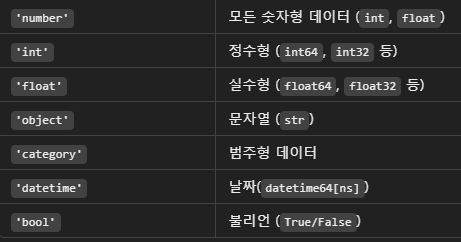
| 판다스 | 파이썬 | |
| 정수형 데이터 | int64 | int |
| 실수형 데이터 | float64 | float |
| 문자열 데이터 | object | string |
| 시간 데이터 | datetime64 timedelta64 |
없음 (datetime 라이브러리 활용) |

x.astype vs float(x)
astype은 시리즈 전체에 적용하는 메서드이다.


6) select_dtypes(include =['??'])
선택하고싶은 데이터타입만 뽑아낼 때 사용한다.
df.select_dtypes(include=['number'])
df.select_dtypes(include=['object'])
df.select_dtypes(include=['float', 'object'])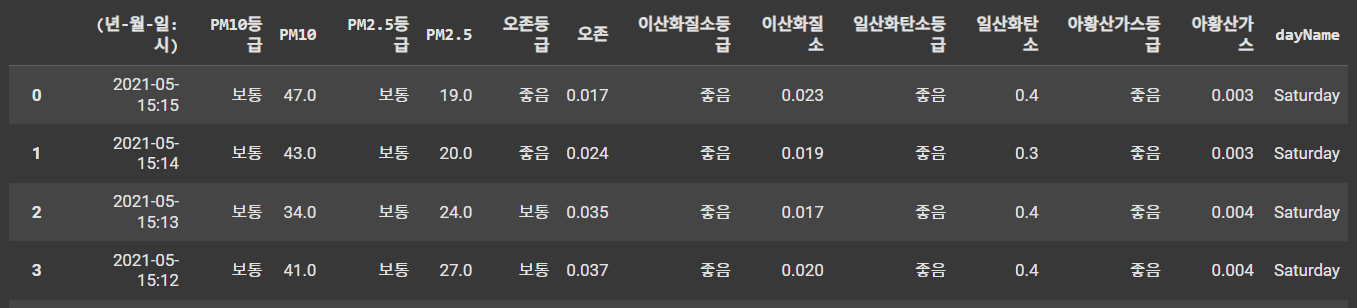
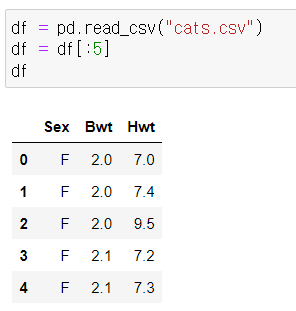
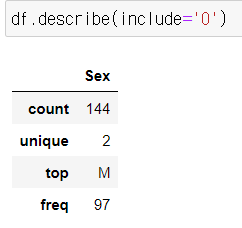
7) describe()
기술통계정보
- count, mean, std, min, 4분위값, max
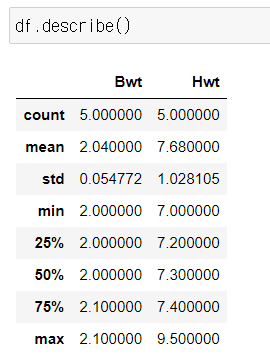
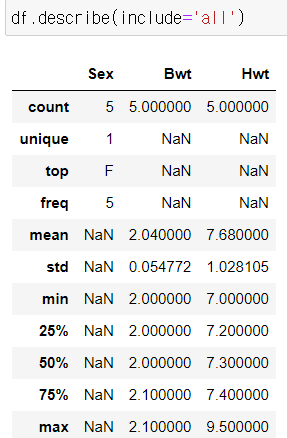
include="all"
include="O"
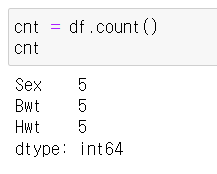
8) count() vs size()
count()
각 열의 유효한 값의 개수 계산
결측값 제외함
size()
그룹화된 데이터에서 각 그룹의 행의 수를 반환
결측값 포함

9) value_counts()
각 열의 고유값이 갖는 개수를 센다.
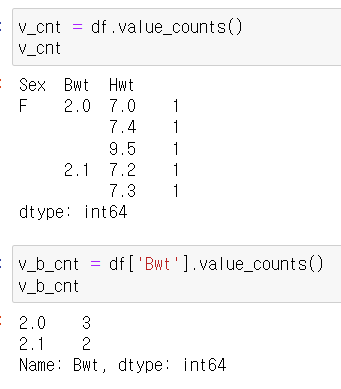
기본적으로 null값은 제외하고 보여주는데, null값의 개수도 보여주게 하려면
.value_counts(dropna=False)

10) unique()
Series.unique()
각 열이 갖는 고유값을 보여준다.

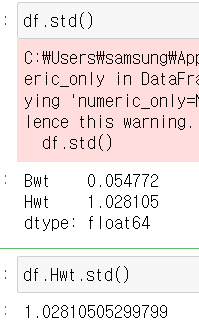
11) 통계 함수
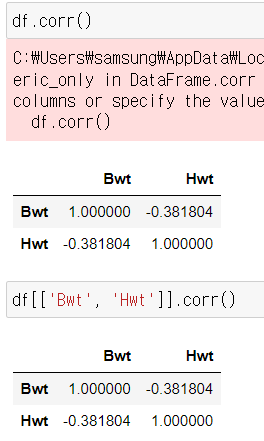
mean(), median(), max(), min(), std(), corr()
모든 열 또는 특정 열에서 사용 가능
4. 데이터 수정
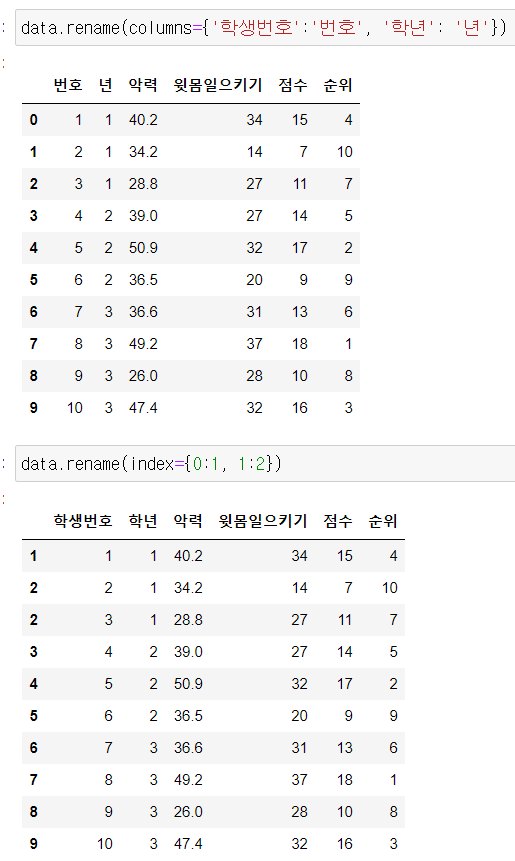
1) rename
index, column 이름 변경
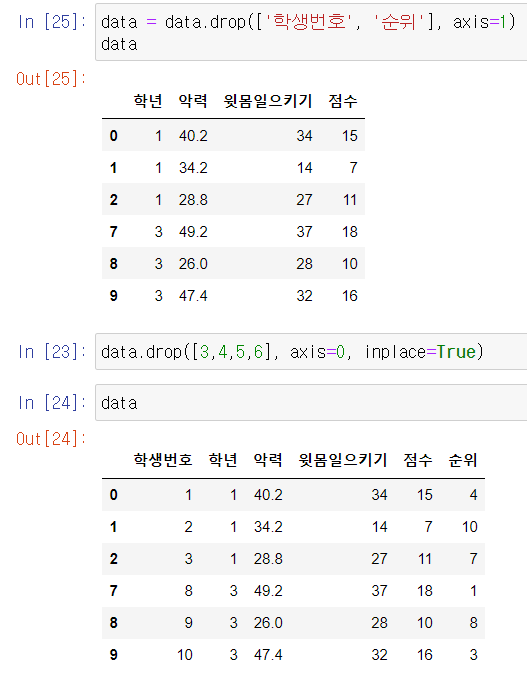
2) drop
row, column 삭제
inplace=True 실제 값 수정
axis=1, axis=0 에 따라 열인지 행인지 기준 선택
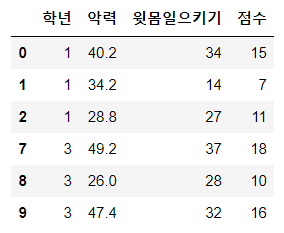
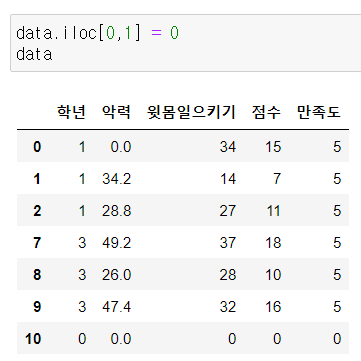
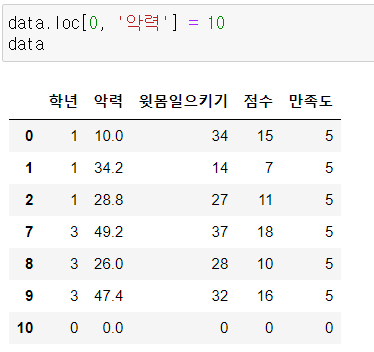
3) loc, iloc
행, 열, 원소 선택
loc : 이름이 기준이 됨, 범위의 끝 포함
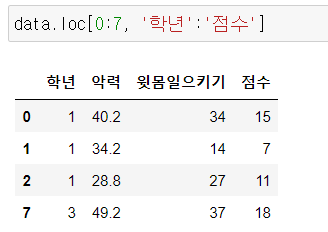
iloc : index 숫자 그 자체에 의미가 있음, 범위의 끝 제외
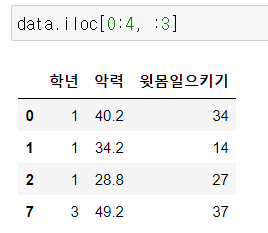
4) 추가
- 열추가
DataFrame['추가하려는 열 이름'] = 데이터값
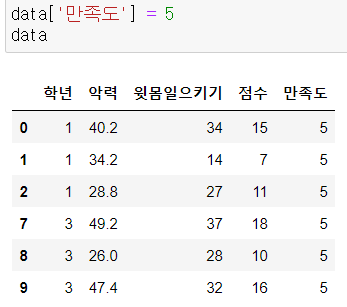
- 행추가
DataFrame.loc['추가하려는 행 이름'] = 데이터값
* iloc은 안됨
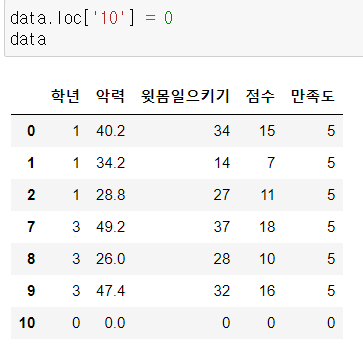
5) 변경
loc / iloc
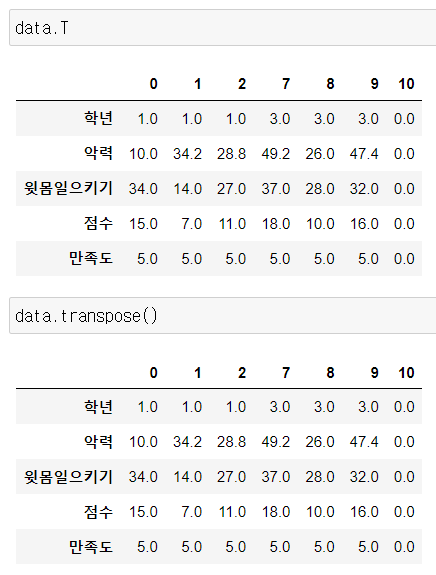
6) Transpose
행과 열 바꾸기
DataFrame.transpose() / DataFrame.T
7) 열 순서 바꾸기
- columns 대입하기
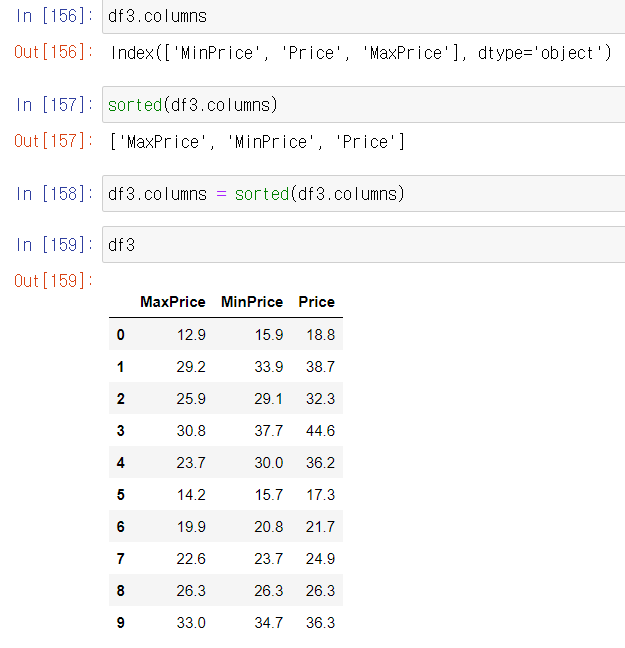
- 객체에 컬럼 지정하기
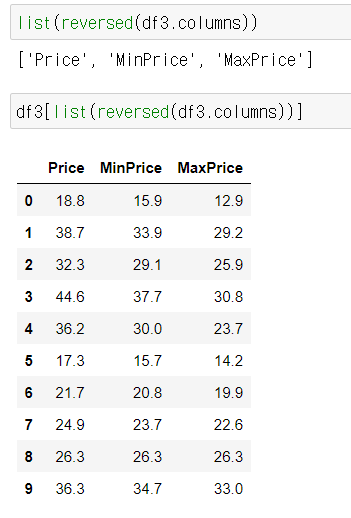
8) 열 분리 & 추출
가. 함수 이용
- 날짜 값인 date열에 주목
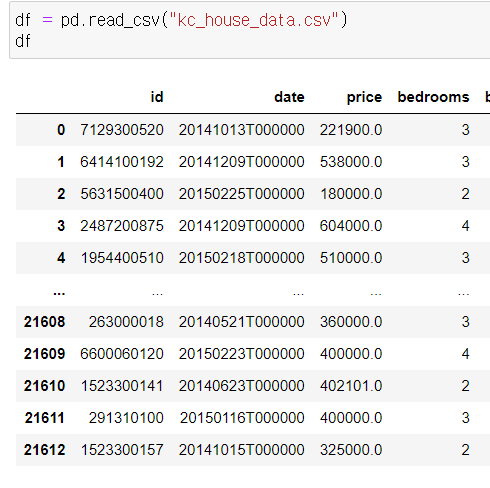
연월일(yyyymmdd형식)까지만 추출
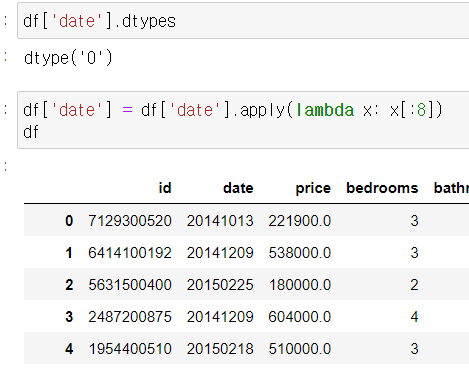
연/월/일 추출
- lambda함수 이용
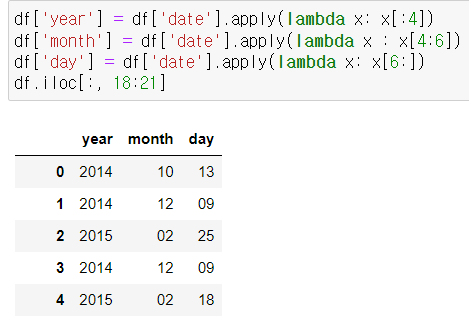
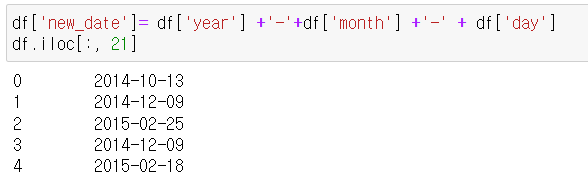
- get함수 이용
*우선 -로 연결된 날짜데이터생성
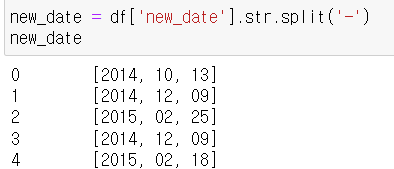
*문자열메소드인 split로 list 속성의 시리즈 만들기
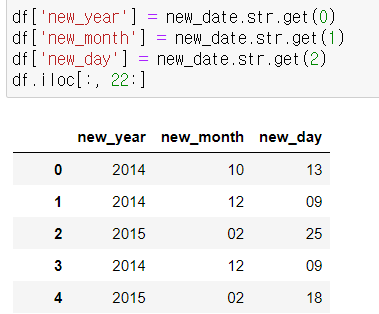
*get() 함수로 값 추출하기
나. 정규표현식 regex 사용

* contains
해당 정규식이 포함되어 있는 행 추출
regex=False : 정규식 없이 단순한 문자열로 찾고 싶은 경우
case = False : 대소문자 구분하지 않은 경우
(1) 한국어
[가-힣]
diff_location['region'].str.contains('부산광역시[가-힣]+')# 여집합 추출
# 부산광역시라고 안붙어있는 모든 것 추출
~diff_location['region'].str.contains('부산광역시[가-힣]+')

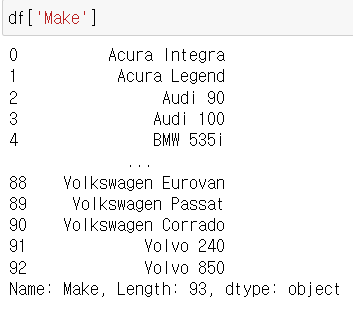
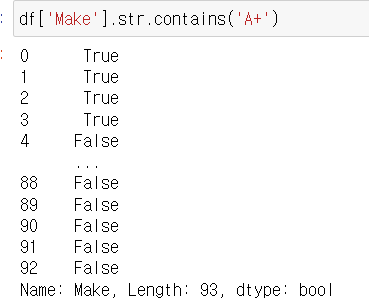
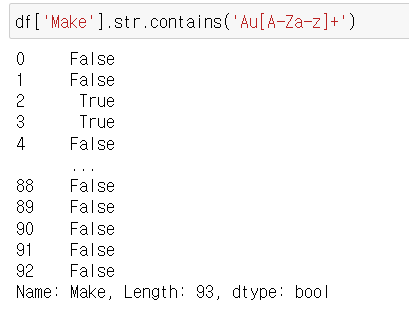
(2) 영어
[A-Za-z]
(3) 숫자
[0-9]


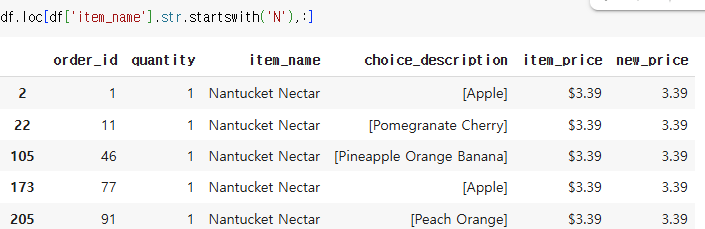
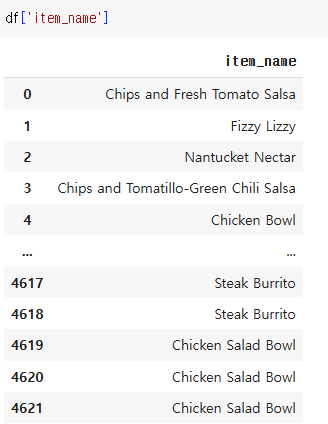
ex) Chips 단어가 포함된 행 모두 추출하기
df['item_name'].str.contains('Chips')
해당 행 보기
df.loc[df['item_name'].str.contains('Chips'), :]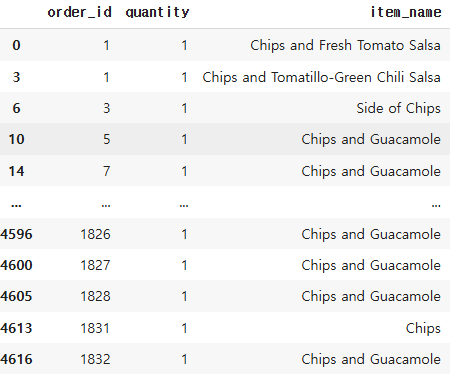
*extract
해당 정규식이 포함되어 있는 값 추출
'( )' 안에 넣어야 함
expand=True : 결과를 데이터프레임형태로 반환
expand=False : 결과를 시리즈 형태로반환
df['Make'].str.extract('(A[A-Za-z]+)')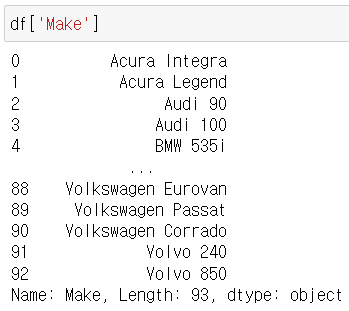

*findall
문자열에 포함된 모든 정규식표현을 추출
리스트로 반환
- 한자리 숫자 : r'\d'
- 연속된 숫자 : r'\d+'
- 문자열에 있는 모든 숫자 리스트로 추출 : (r'\d+')
df['Make'].str.findall('[A-Za-z]+')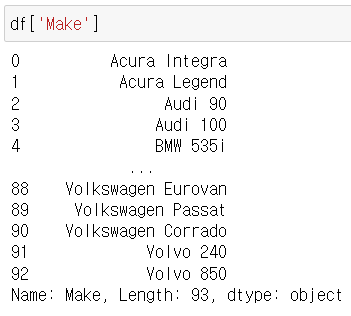

.str의 역할
판다스 시리즈에 문자열 메서드를 적용하고자 할 때 쓴다.
문자열 메서드 : upper(), lower(), replace(), slice() 등
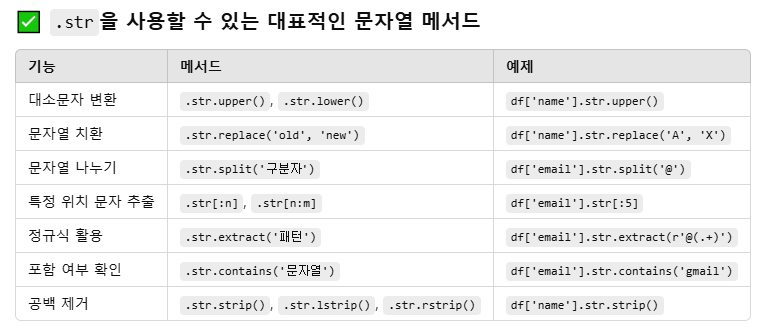
startswith(), endswith(), find()
startswith()
문자열이 특정 문자들로 시작하는지 확인하는 메서드
대소문자를 구분함
endwith()
문자열이 특정 문자로 끝나는지 확인하는 메서드
대소문자를 구분함

find()
문자열 안에서 특정 문자의 위치를 찾음. 없으면 -1

5. 인덱스
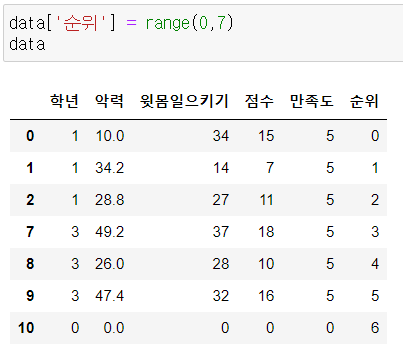
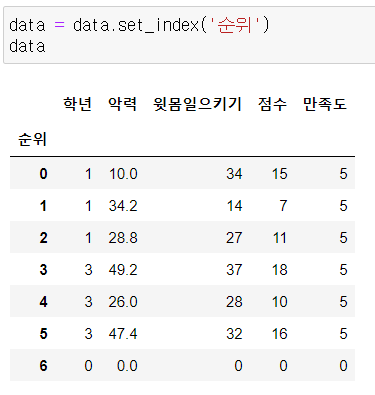
1) set_index
특정 열을 행 인덱스로 설정
기존 인덱스는 삭제
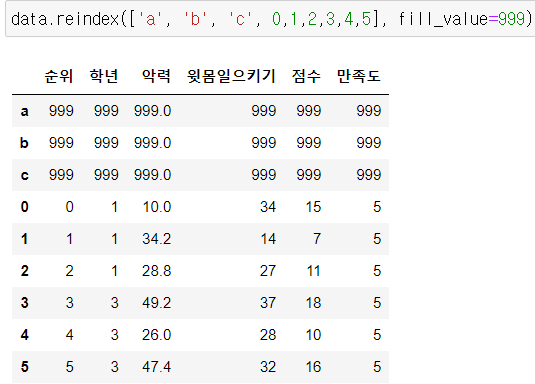
2) reindex()
행 인덱스 재배열
기존 DataFrame에 포함되지 않은 행인덱스는 NaN값으로 입력됨
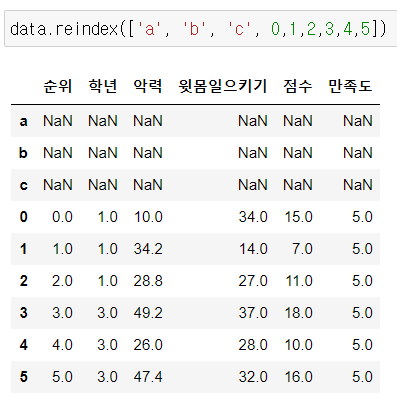
NaN값 채우려면 fill_value 넣기
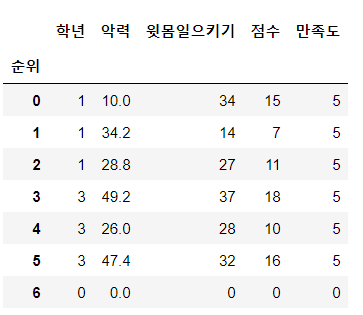
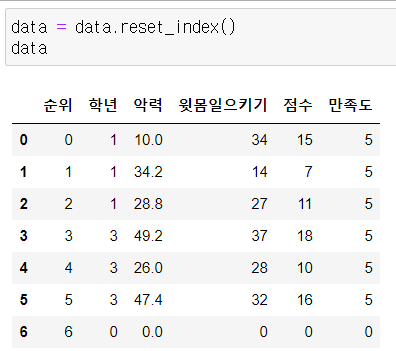
3) reset_index
행인덱스 초기화 (0,1,2,3,4,,,)
기존의 행인덱스는 첫 번째 열로 이동
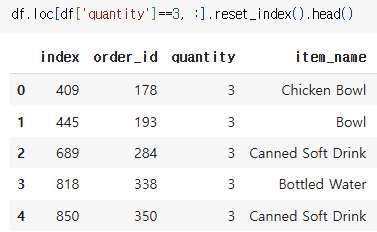
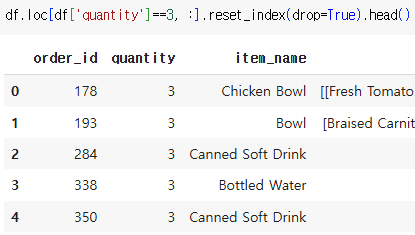
drop=True
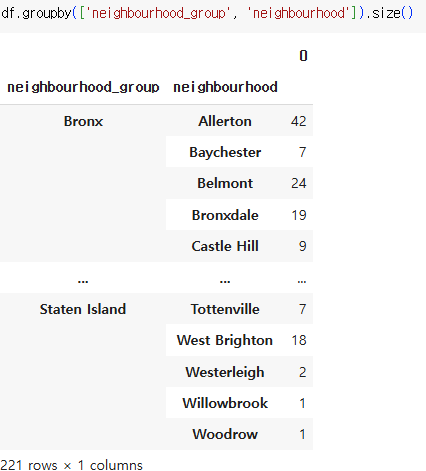
4) as_index= True/False
groupby는 그룹화된 컬럼을 인덱스로 사용하여 결과를 반환한다.

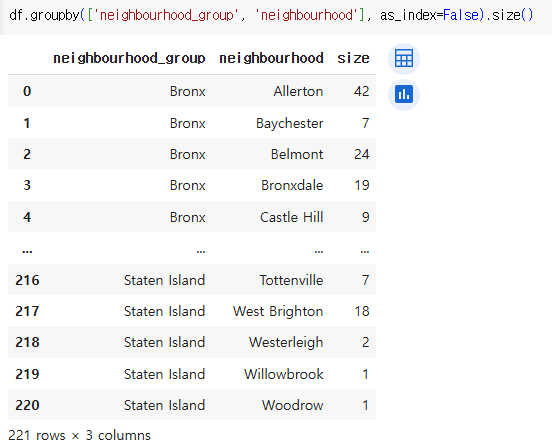
그룹화된 결과를 DataFrame 형태로 반환하도록 만드는 옵션이다.
as_index=False는 그룹화된 컬럼들이 일반적인 열로 포함되며, 인덱스는 기본 순서대로 설정된다.
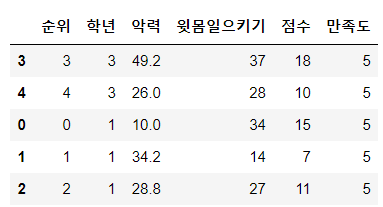
6. 정렬
1) sort_index(ascending=? )
행 인덱스 기준으로 데이터프레임 값 정렬
ascending =True 오름차순
ascending = False 내림차순
2) sort_value(by =?, ascending=? )
특정 열을 기준으로 오름차순 /내림차순 정렬
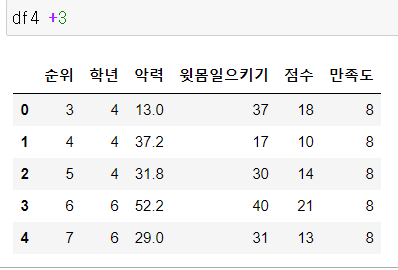
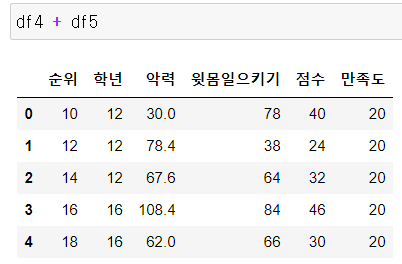
7. 연산
원리
같은 것끼리 계산함
그러기 위해서
1단계 행/열 인덱스 기준으로 원소 정렬
2단계 동일한 위치 원소끼리 1:1 대응
3단계 연산처리


8. 필터링
1) mask
- 비트연산자 & , |
- ( ) 괄호 필수!
※ and/or 연산자는 두 개의 불린 값에서만 작용하기 때문에 안됨
mask = (df.Price>20) & (df.Price <30)
df[mask]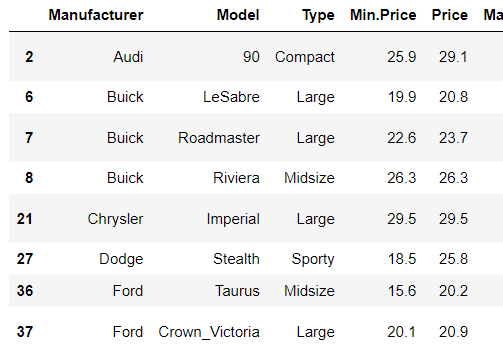
- loc 이용 가능
df.loc[mask, ['Type','Price']]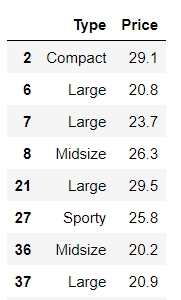
- 관계연산자 ==, !=
mask1 = df['MPG.city']==25
mask2 = df['MPG.city'] == 20
mask3 = df['MPG.city']==22
df[mask1|mask2|mask3]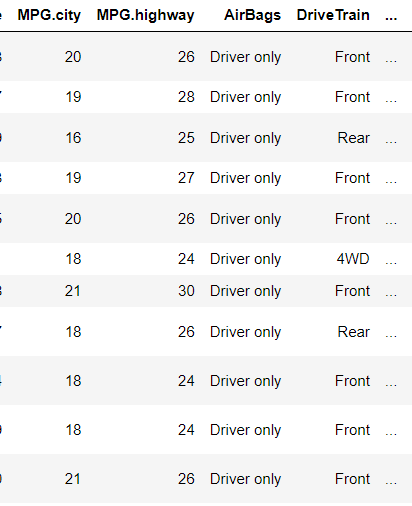
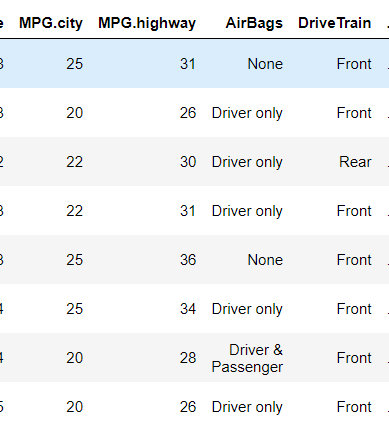
2) isin()
filter = df['MPG.city'].isin([25,20,22])
filter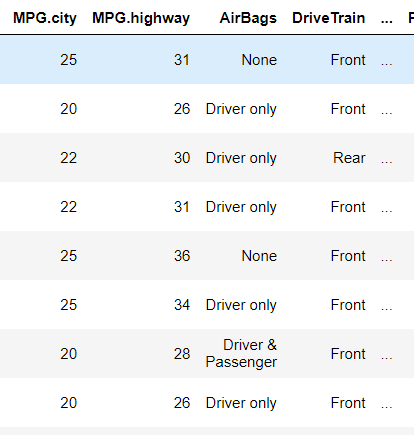
pandas 요약 데이터분석 배우기 ADP 기본기 빅분기 기본기
'파이썬 > 판다스' 카테고리의 다른 글
| pandas 배우기 3편 데이터시각화: 빅분기 ADP 데이터분석 시험, 파이차트, 히스토그램, 박스플랏, 스케터플랏,히트맵 (1) | 2024.11.07 |
|---|---|
| pandas 배우기 2편 데이터전처리 :빅분기 ADP 데이터분석 요약 (0) | 2024.10.11 |
| 판다스 컬럼 항목 일괄 변경, 특정 컬럼 기준 정렬, map 매핑 (0) | 2024.02.15 |
| [판다스 10분 요약 10] 판다스 시각화(matplotlib, csv, HDF5, excel) (0) | 2022.09.06 |
| [판다스 10분 요약 9] Grouping 데이터 그룹화 (0) | 2022.09.06 |