이번 편에서는 pandas가지고 데이터전처리 하는 방법을 공부해본다. 빅분기 ADP 데이터분석 시험 공부 요약 이라고 생각하면 좋다. 시작해보자!
1. null값
1) null값 찾기
★ isnull() = isna() : Null인것이 True
★ notnull() : NotNull인것이 True

2) 개수 구하기
★ sum()
axis = 0
axis = 1
축의 방향에 따라 sum()의 값이 달라짐
3) 제거
★ dropna()
axis=0, axis=1 이냐에 따라 제거되는 방향이 달라진다.
기본은 axis=0이다. 누락 행을 삭제
axis=1은 누락 열을 삭제
★ subset= [컬럼이름]
전체가 아니라 특정 열만 한정하는 경우는 subset을 쓴다.
★ how = 'any', 'all' ?
any : 기본값. NaN값이 하나라도 존재하면 삭제
all : 모두다 NaN값인 경우에만 삭제
< axis=1 >
< axis=0 >
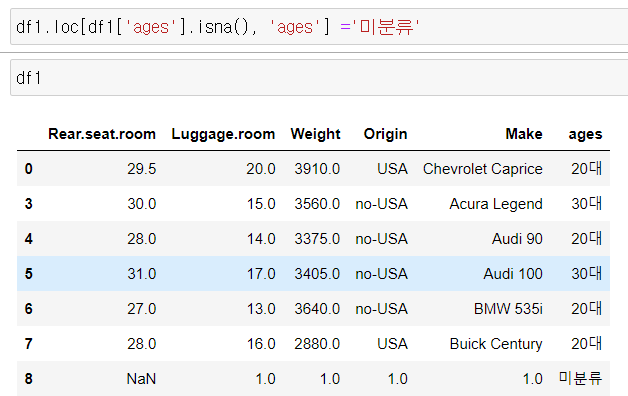
4) 채우기
가. fillna
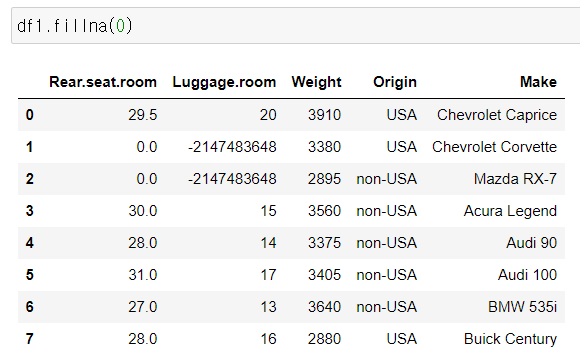
- inplace =True
원본데이터 변경
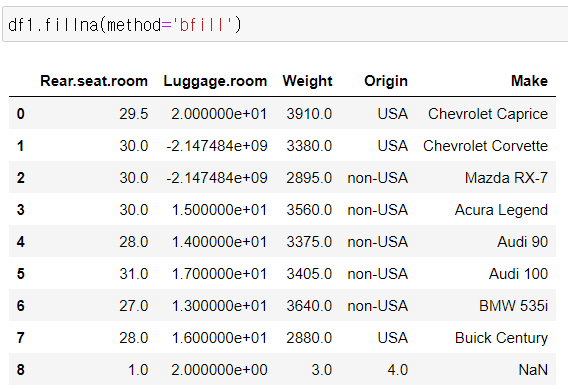
★ method = 'ffill'
method = 'bfill'
ffill : front fill 앞에 값으로 채우기
bfill : back fill 뒤에 값으로 채우기
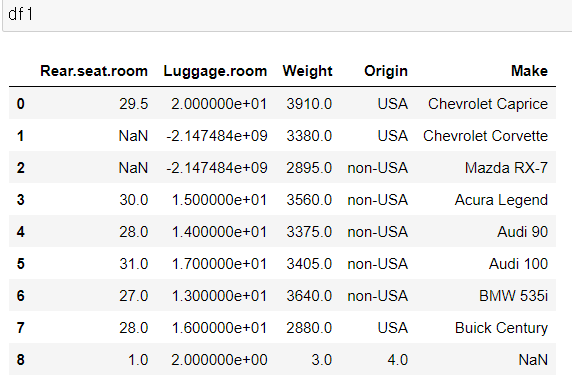
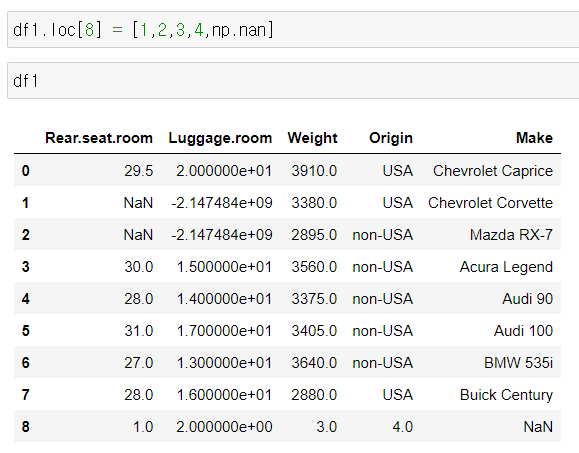
나. np.nan
null 값으로 채우기
np.nan 으로 널값을 임의로 넣을 수도 있음
2. 중복 데이터
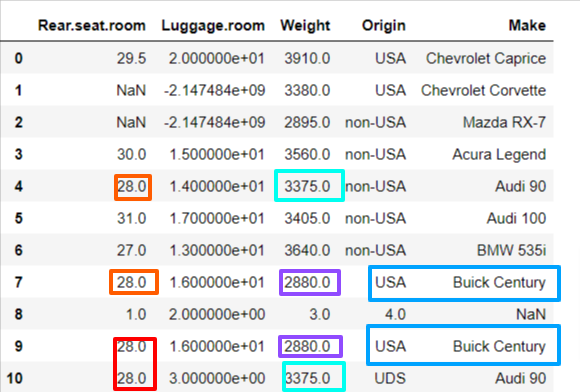
1) duplicated()
관측값 중복되는지 확인
기본적으로 행을 기준으로 함
최초의 것은 남겨두고, 두 번째부터 중복인 것에 대해 중복데이터라 칭함

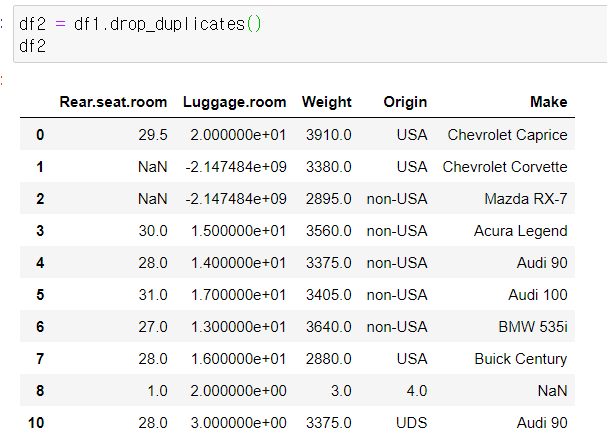
2) drop_duplicates()
중복 데이터 제거
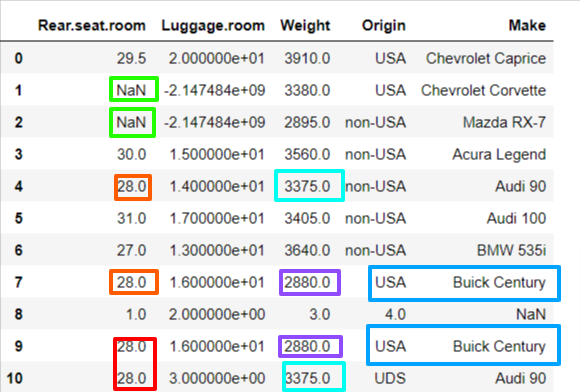
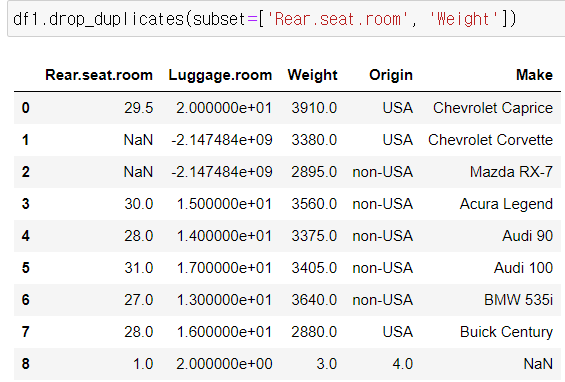
- ★ subset=[특정 컬럼]
특정 컬럼 안에서만 판별한다.
★ .duplicated(subset=[])
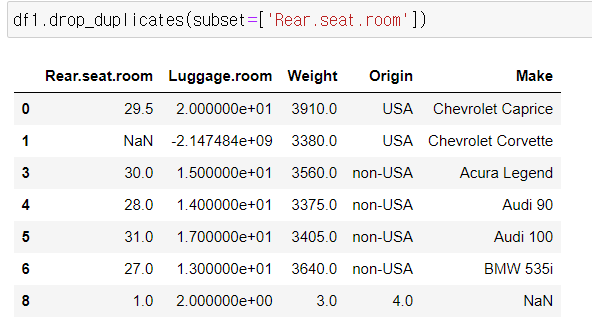
아래의 경우 Rear.seat.room에서만 중복된 데이터를 확인하는거다.
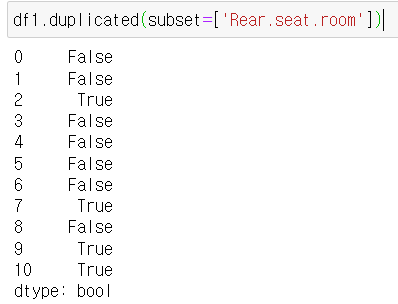
★ .drop_duplicates(subset=[])
3. 데이터표준화
ex) 단위 맞추기
cm / m / L / gram / inch 등
| dtypes | astype | replace |
| 자료형확인 | 자료형 변환 | 직접 변환 |
| df1.Origin.dtypes df1.dtypes |
df3.astype('int') df3['Price'].astype('int') |
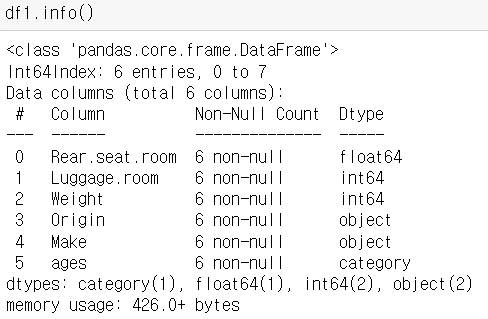
1) dtypes

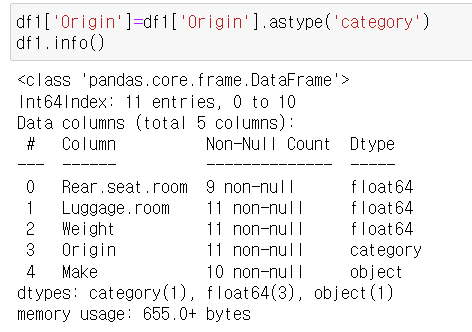
2) astype
- 문자열 > 카테고리형
- 카테고리형 > 문자열
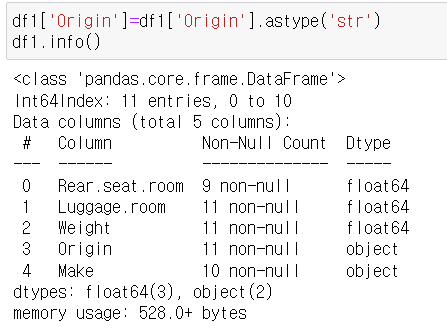
astype vs float
astype은 시리즈 전체에 적용하는 메서드이다.


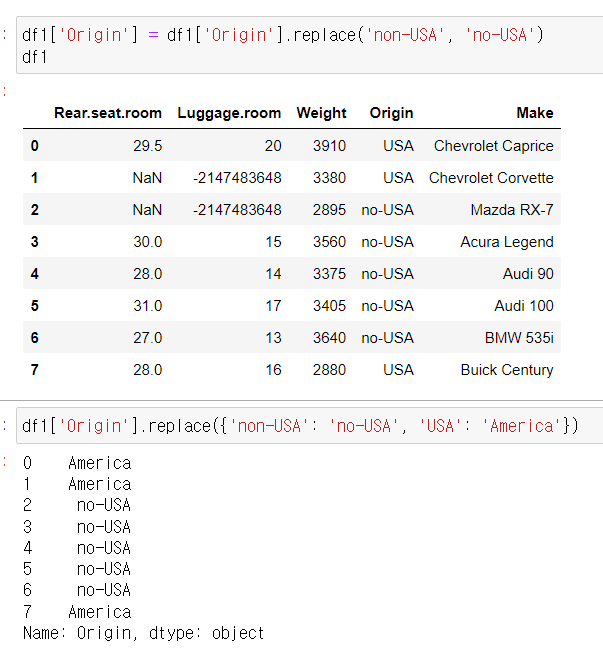
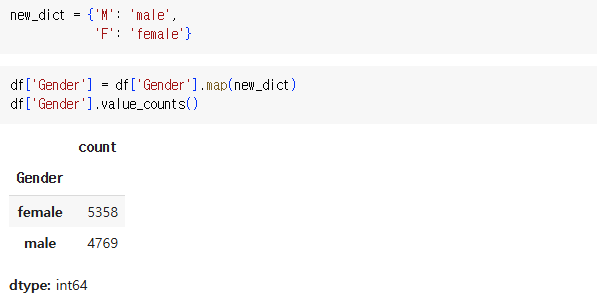
3) replace
df, series 모두 적용됨
.replace(a, b)
.replace({a:b, c:d})
4. 카테고리 데이터 처리
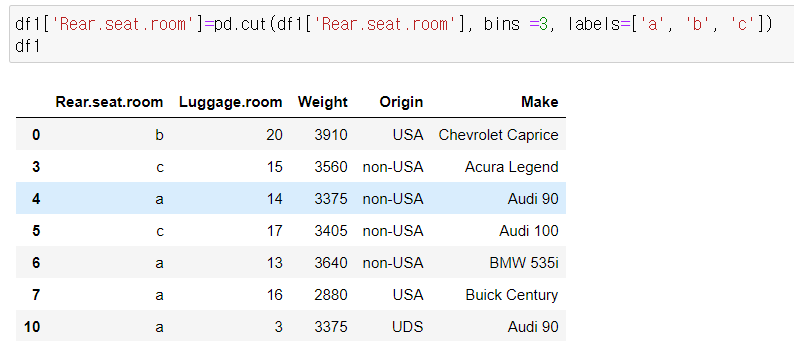
1) pd.cut(데이터, bins, labels, right)
숫자값 -> 카테고리값
데이터를 지정된 구간(bins)으로 나누어 경계값을 반환함
★ - bins : 구간 설정
★ - labels : 각 구간에 해당하는 레이블 이름
>> bins가 4개면, labels은 3개여야 함
★ - right : 오른쪽 경계 포함하는지 여부
- retbins=True 경계값 리스트만 반환 가능

카테고리형 데이터로 변환됨
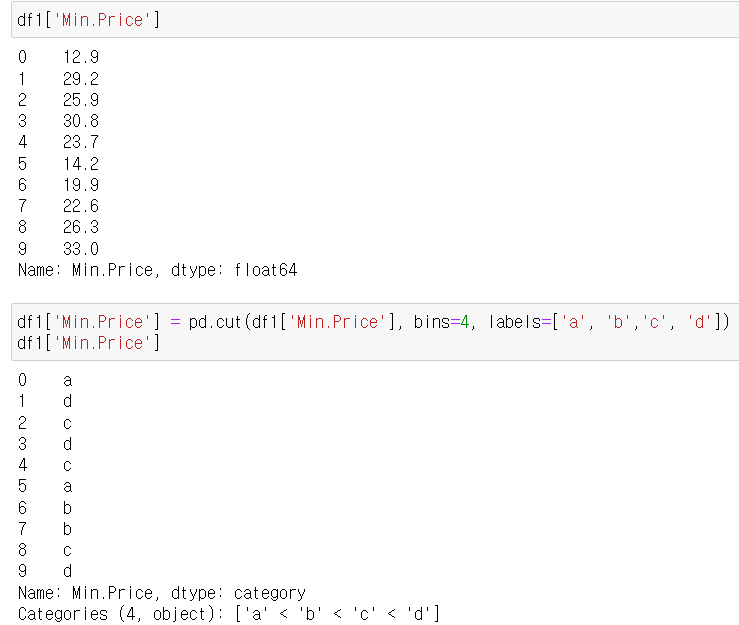
범위 주지 않고 bins 개수만 주는 방법 : 경계값 구하기
★ pd.cut(데이터, bins=개수)

구간에 해당하는 값= lables 입력하기
pd.cut(데이터, bins=개수, labels=구간이름)
< 다른 예시 >
2) pd.qcut(data, q=?, retbins=?)
데이터를 분위로 나눌 때 유용함
3) .cat
? -> 카테고리형 변환된 데이터 속성 접근
( str일 때는 .str으로 접근하는 것과 같음)
- 카테고리 목록 확인
.cat.categories

- 카테고리 추가
.cat.add_categories(새로운카테고리이름)

- 특정 데이터를 특정 카테고리값으로 변환
(만약 카테고리 목록에 변환하고자 하는 특정 카테고리값이 없다면 에러 뜸)
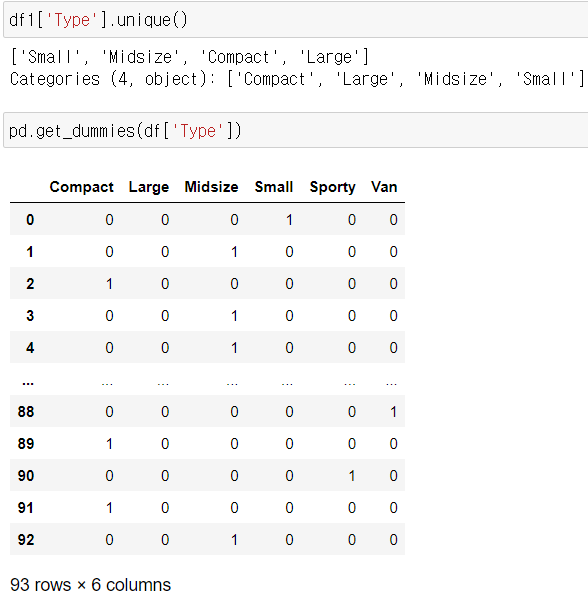
4) get_dummies()
더미변수 (원핫인코딩)
5. 정규화
각 열 값의 숫자 데이터 상대적 크기 차이가 나중에 머신러닝 학습 시에 가중치와 연결이 되어 결과값에 왜곡이 생길 수 있다. 각 열 값에 대해 정규화 작업을 해주면 해당 왜곡을 피할 수 있다. 각 열 데이터값을 동일한 크기 기준으로 나타내느느 것을 정규화라고 한다.
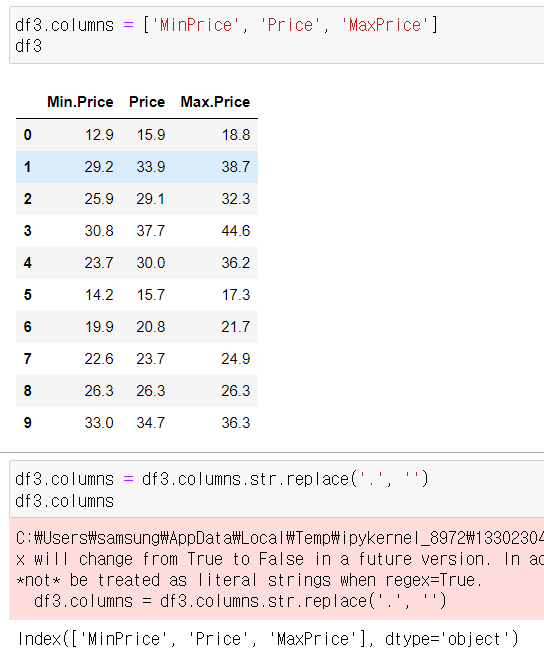
* column명 변환
- 컬럼에 .(점) 포함되어 있으면 OLS formula 적용 안됨
1) standardScaler
평균0, 분산 1
표준정규분포를 가진 데이터셋으로 변환
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
std_scaled_data = scaler.fit_transform(df3)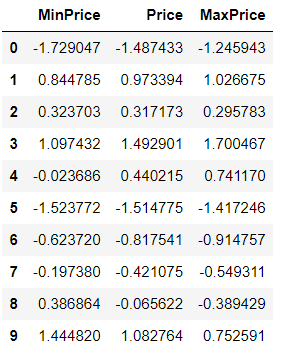
2) MinMaxScaler
최소값 0, 최대값 1
음수값이 있다면 최소값 -1, 최대값 1
from sklearn.preprocessing import StandardScaler, MinMaxScaler
scaler = MinMaxScaler()
mm_scaled_data = scaler.fit_transform(df3)
pd.DataFrame(data= mm_scaled_data, columns = df3.columns)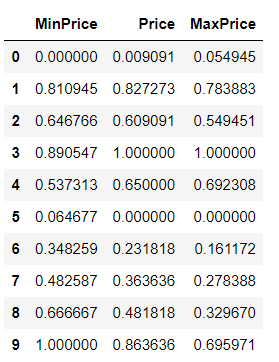
3) log Transformation
각 데이터에 log함수 적용하여 정규분포와 가까운 형태로 변환
np.log1p() : 1+log()함수 언더플로우 발생 방지
import numpy as np
log_scaled_data = np.log1p(df3)
log_scaled_data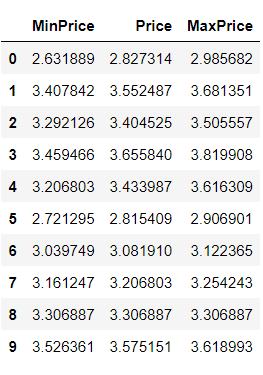
6. 함수 매핑
1) DataFrame 자체 -> 개별원소 연산
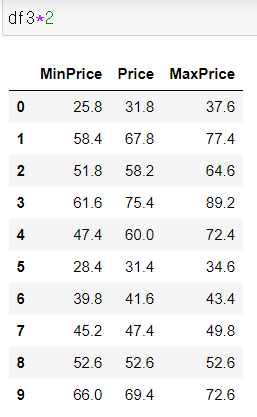
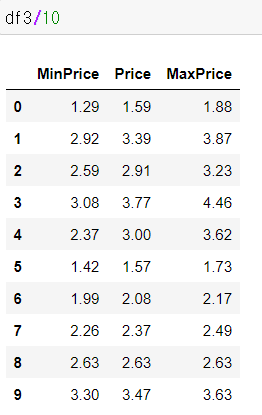
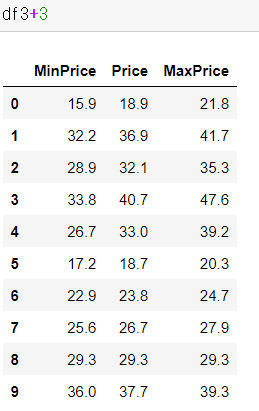
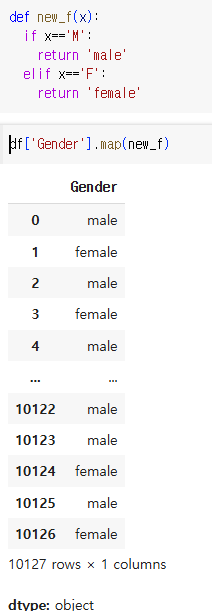
2) applymap(), map()
데이터프레임 개별 원소에 접근해 특정 함수를 매핑함
요즘엔 applymap < map
- 기본함수
- 사용자정의함수
- 람다함수
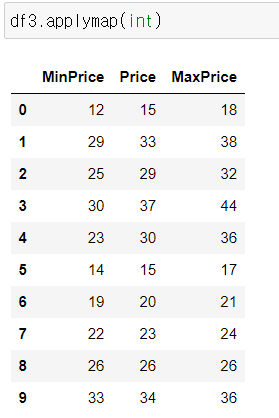
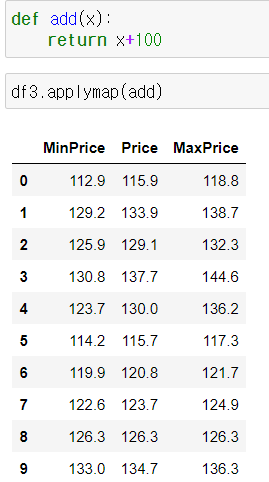
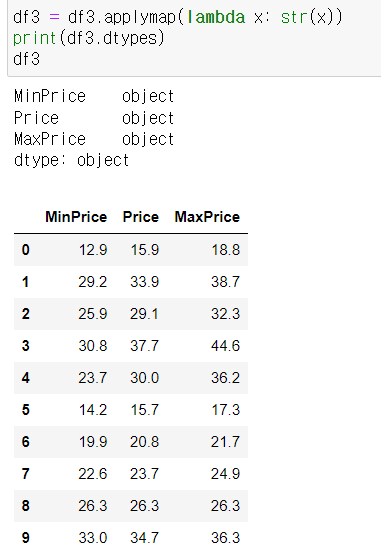
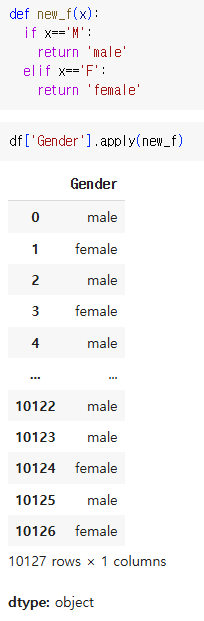
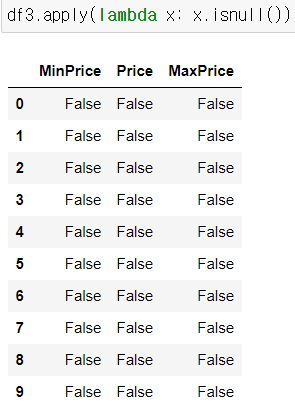
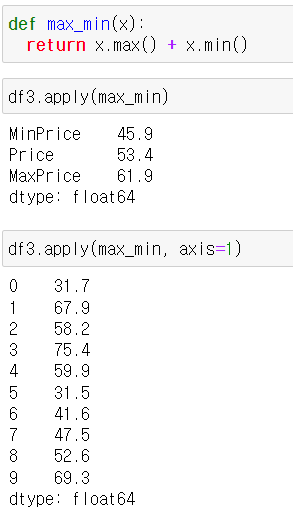
3) apply()
가. 시리즈에 접근
Series.apply(함수)
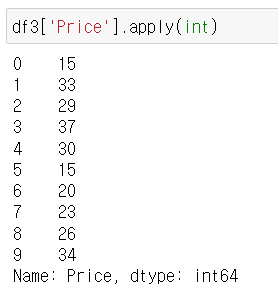
Series.apply(함수, 인수 = ?)
인수를 적어줘도 됨
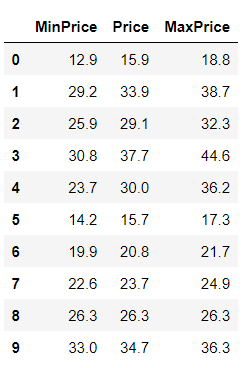
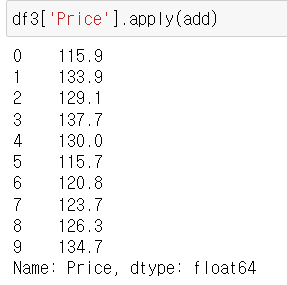

Serires.apply(lambda함수)
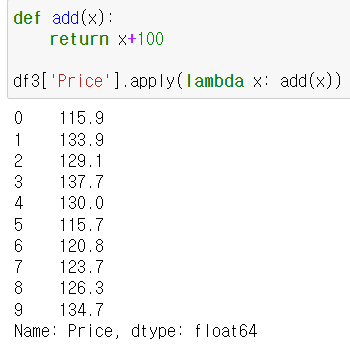
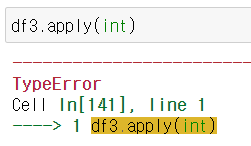
* 만약 df.apply(add함수)를 하게 되면 에러가 남.
이 경우에는 함수가 받는 인수가 df의 열 또는 행 자체가 된다. 따라서 불가능.
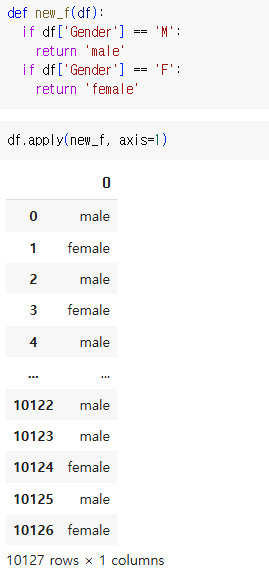
\
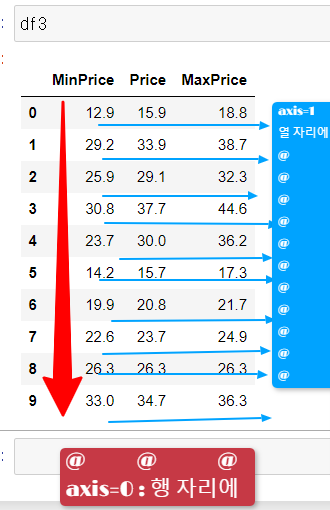
나. 데이터프레임 객체에 접근
- df의 행 또는 열을 apply 뒤의 함수가 받는다
- df의 각 열에 함수 매핑 axis=0 (default값)
- df의 각 행에 함수 매핑 axis=1
7. 데이터프레임 합치기
1) pd.concat([데이터프레임1, 데이터프레임2], axis=?, join = ?)
concat은 물리적으로 합치는 것이다.
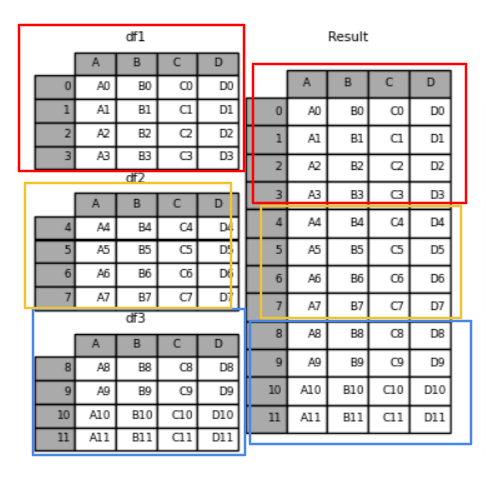
* axis=0 (기본)
df1 = df[['Type', 'Price']].iloc[:5]
df2 = df[['Model', 'Price']].iloc[:5]
pd.concat([df1,df2], axis=0)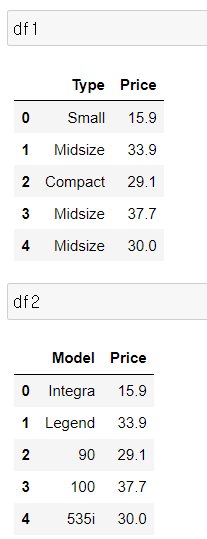
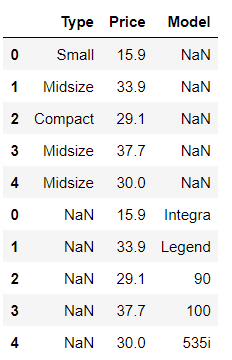
* axis =1
pd.concat([df1, df2], axis=1)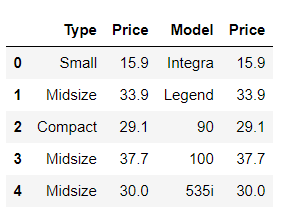
* 합집합: join ='outer' (기본)
교집합: join='inner
pd.concat([df1,df2], axis=0, join='inner')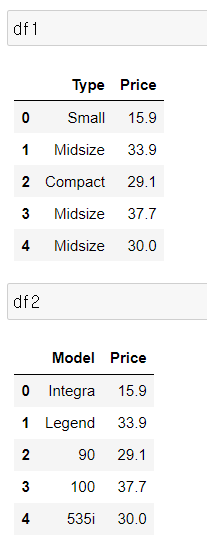
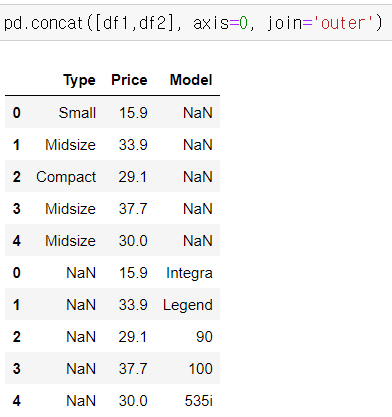
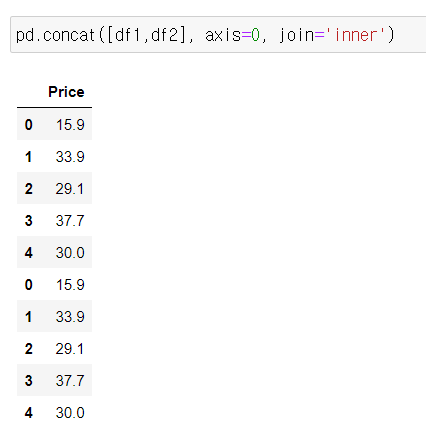
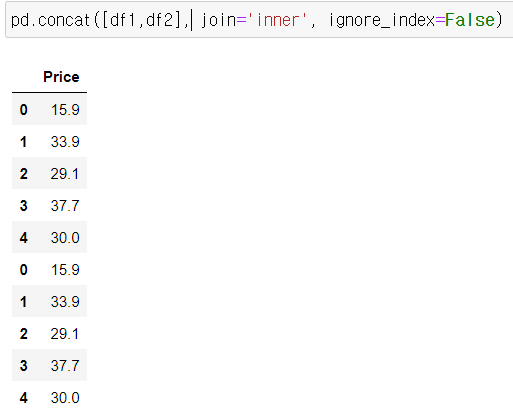
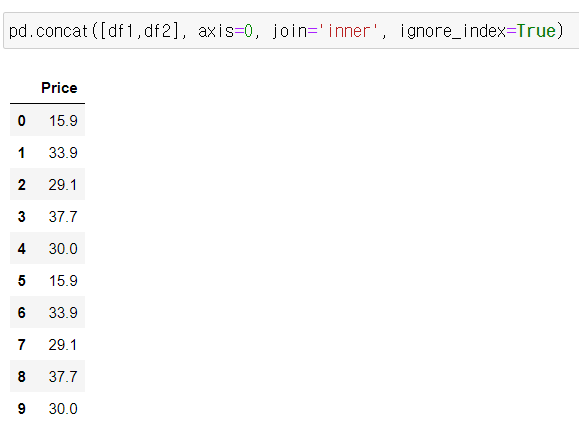
* ignore_index = True
기존 행인덱스 무시하고 새롭게 설정
2) pd.merge( 데이터프레임1, 데이터프레임2, how=?, on=?)
두 데이터프레임을 병합한다.
즉, 어떤 '기준'에 의해 두 프레임을 '병합'한다는 것인데
두 데이터프레임에 모두 존재하는 열이나 인덱스가 기준이 된다.
기준이 되는 열이나 인덱스를 key라고 부른다.
* ★ on = 기준이되는 열 or 인덱스
만약 on = None이라면, 두 df에 공통으로 속하는 모든 열을 기준으로 병합하라는 뜻이다.
* ★ how = 'outer' / 'inner'
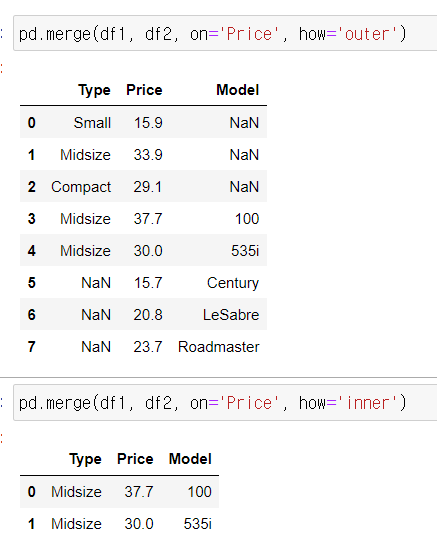
pd.merge(df1, df2, on='Price', how='outer')
pd.merge(df1, df2, on='Price', how='inner')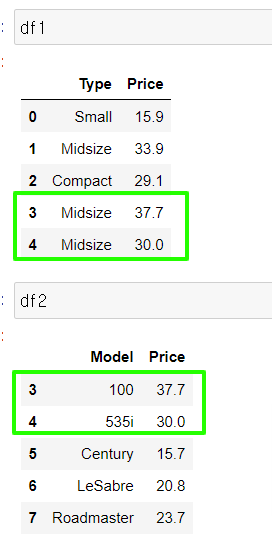
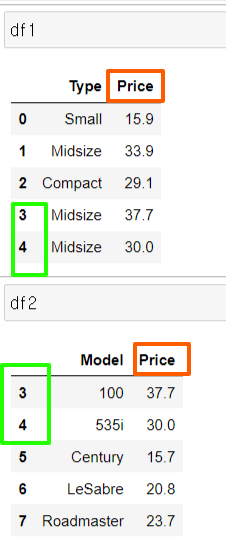
3) 데이터프레임1.join(데이터프레임2, how=?)
merge와 비슷한 병합의 기능을 하지만, 다른 점은 '행 인덱스'를 기준으로 결합한다는 것이다.
하지만 on=keys 옵션 설정하면 다른 열 기준으로 병합 기능 가능하다.
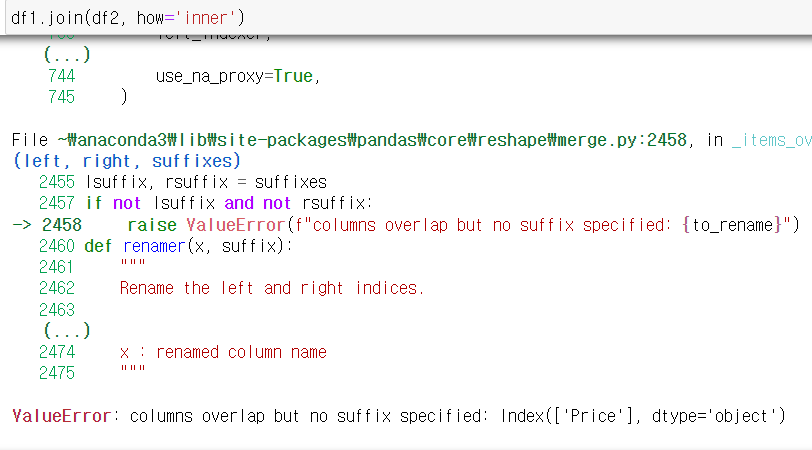
* 두 데이터프레임 열의 이름이 겹친다면? suffix 접미사를 어떻게 설정하는지 표시해야 한다.
★ lsuffix : 왼쪽 데이터프레임1에 대한 suffix
★ rsuffix : 오른쪽 데이터프레임2에 대한 suffix
df1.join(df2, how='inner', lsuffix='left', rsuffix='right')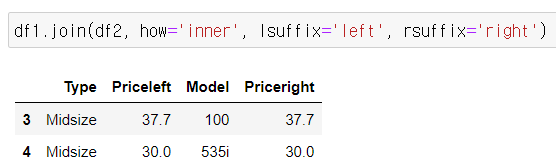
df1.join(df2, how='outer', lsuffix='left', rsuffix='right')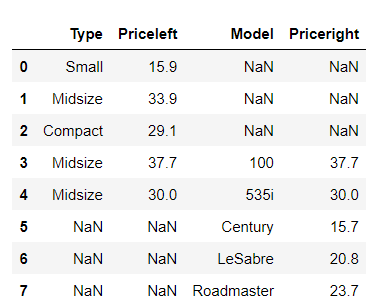
8. groupby
1) agg() 함수 종류
mean, min, max, count, median
sum
var, std(표준편차: 평균을 기준으로 얼마나 흩어져 있는지 변동성 확인)
first, last, unique
prod(곱: 각 그룹의 값을 모두 곱함) , sem(표준오차)
< data4 >
2) 컬럼별 agg 함수 적용
data4.groupby('author_ban_status')['likes_per_view', 'comments_per_view', 'shares_per_view'].agg(
['median', 'count', 'mean'])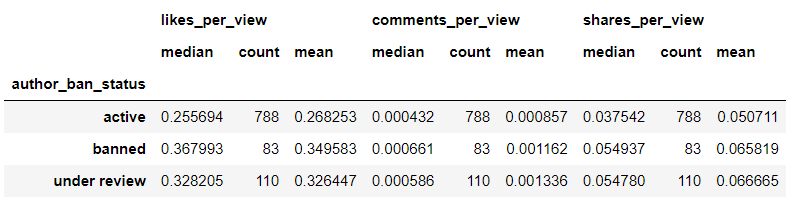
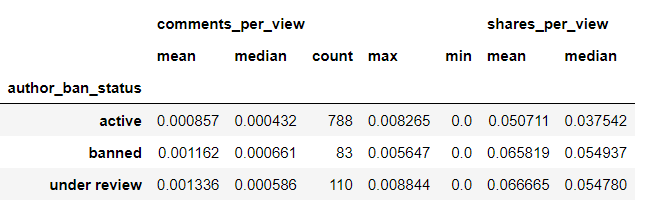
3) key:value 별로 agg함수 적용
data4.groupby(['author_ban_status']).agg({
'comments_per_view':['mean', 'median', 'count', 'max', 'min'],
'shares_per_view':['mean', 'median' ]
})
4) agg : std 표준편차 해석
'likes_per_view' : ['std'] 라고 하면 column값에 std 표시됨.
data4.groupby(['author_ban_status']).agg(
{'likes_per_view': 'std',
'comments_per_view': 'std',
'shares_per_view': 'std'})
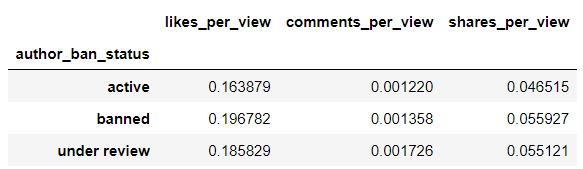
- 표준편차 높으면 다른 상태에 비해 더 다양한 분포를 보임, 변동성 높음
- 표준편차 작으면 다른 상태에 비해 더 일정한 분포를 보임, 일관성 있음
pandas 배우기 2편 데이터전처리 :빅분기 ADP 데이터분석 요약
'파이썬 > 판다스' 카테고리의 다른 글
| pandas 배우기 4편 데이터 전처리 : upsampling(업샘플링), outlier(이상치) , 상관관계, 차원변환 (0) | 2024.11.08 |
|---|---|
| pandas 배우기 3편 데이터시각화: 빅분기 ADP 데이터분석 시험, 파이차트, 히스토그램, 박스플랏, 스케터플랏,히트맵 (1) | 2024.11.07 |
| pandas 배우기 1편 EDA : 빅분기 ADP 데이터분석 시험 요약 (0) | 2024.10.11 |
| 판다스 컬럼 항목 일괄 변경, 특정 컬럼 기준 정렬, map 매핑 (0) | 2024.02.15 |
| [판다스 10분 요약 10] 판다스 시각화(matplotlib, csv, HDF5, excel) (0) | 2022.09.06 |