지난 시간 csv 라이브러리로 데이터를 처리했다.
(복습) csv 라이브러리로 csv 데이터처리하기 -----> 클릭
오늘은 판다스 pandas로 똑같은 데이터를 처리할 것인데
과정이 매우매우 단순해진다.
판다스는 매우 잘 만들어진 라이브러리다.
앞으로 데이터 처리에 있어서 자주 쓰게 될 것이다.
1. pandas 공식문서 - API reference

pandas에 관한 모든 설명과 지침을 얻을 수 있다.
2. pandas 불러오기
파이참에서 import pandas를 적고
마우스를 가져다 대면, 빨강색 전구가 보이는데
그것을 클릭하면 자동 install(설치)이 된다.
그리고 아래의 파일을 저장하고, 읽어온다.
import pandas
data = pandas.read_csv("weather_data.csv")
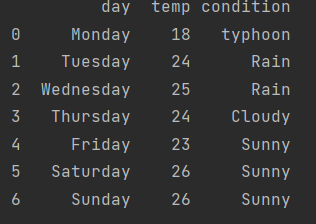
print(data)데이터가 열(칼럼 column)과 행(로우 row)으로 아주 가지런하게 보기 쉽게 정리되어 나온다.
index도 있어 순서도 찾기 쉽다.
3. to_dict()

데이터프레임을 dictionary 형태로 바꿔준다.
import pandas as pd
data = pd.read_csv("weather_data.csv")
data_dict = data.to_dict()
print(data_dict){'day': {0: 'Monday', 1: 'Tuesday', 2: 'Wednesday', 3: 'Thursday', 4: 'Friday', 5: 'Saturday', 6: 'Sunday'},
'temp': {0: 18, 1: 24, 2: 25, 3: 24, 4: 23, 5: 26, 6: 26},
'condition': {0: 'typhoon', 1: 'Rain', 2: 'Rain', 3: 'Cloudy', 4: 'Sunny', 5: 'Sunny', 6: 'Sunny'}}
4. 특정 열(column)에서 데이터 찾기
특정 열에서 데이터를 찾는 방법은 2가지가 있다.
1) . 점 사용하기
내가 원하는 데이터 프레임을 적고,
. 점을 찍은 뒤,
해당 프레임의 첫 번째 행에서 내가 가져오고 싶은 특정 열의 이름을 적으면 된다.
data.속성값으로서, 이것은 데이터를 객체에 가깝게 취급하는 것입니다.
data.condition2) 대괄호 사용하기
내가 원하는 데이터 프레임을 적고,
해당 프레임의 첫 번째 행에서 내가 가져오고 싶은 특정 열의 이름을 [ ] 대괄호 안에 넣으면 된다.
이것은 데이터를 딕셔너리로 취급하는 것입니다.
data["condition"]
예시를 보자.
day, temp, condition 중 temp 데이터만 보고 싶다면
data["temp"]라고 쓴다.
import pandas
data = pandas.read_csv("weather_data.csv")
print(data["temp"])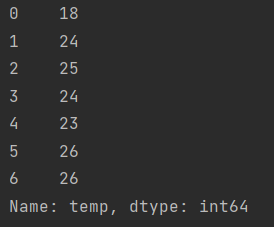
타입을 확인해보면, 시리즈이다.
print(type(data["temp"]))<class 'pandas.core.series.Series'>
5. to_list()

이번에는 이 시리즈에 to_list 메소드를 호출하여
시리즈를 파이썬 list로 바꾼다.
temp_list = data["temp"].to_list()
print(temp_list)[18, 24, 25, 24, 23, 26, 26]
그리고나면, 우리가 아는 파이썬 문법으로 원하는 모든 것을 할 수 있다.
예컨데, 평균 온도를 구하기 위해 sum(), len() 함수를 이용할 수 있다.
average = sum(temp_list) / len(temp_list)
print(average)23.714285714285715
6. mean()

위의 문제를 판다스 메소드를 활용해서 풀어보자.
데이터 시리즈에 알맞는 메소드를 호출해서 다양한 작업을
복잡한 과정을 생략하며, 쉽게 답을 얻을 수 있다.
이용할 메소드는 mean()이다. 평균을 구해준다.
print(data["temp"].mean())23.714285714285715
7. max()

print(data["temp"].max())26
8. 원하는 행 추출하기
불린을 이용하여 원하는 행을 추출한다.
조건으로 원하는 행만 고르는 원리이다.
print(data.temp==data.temp.max())0 False
1 False
2 False
3 False
4 False
5 True
6 True
Name: temp, dtype: bool
print(data[data.temp==data.temp.max()]) day temp condition
5 Saturday 26 Sunny
6 Sunday 26 Sunny
print(data[data.day == "Monday"]) day temp condition
0 Monday 18 typhoon
9. 데이터 프레임 만들기

판다스 라이브러리를 호출해서 DataFrame 클래스를 찾는다.
그리고 데이터로 DataFrame 클래스를 initialize 초기화 한다.
아래에서는 그 데이터가 dict 가 된다.
dict = {
'day': {0: 'Monday', 1: 'Tuesday', 2: 'Wednesday', 3: 'Thursday', 4: 'Friday', 5: 'Saturday', 6: 'Sunday'},
'temp': {0: 18, 1: 24, 2: 25, 3: 24, 4: 23, 5: 26, 6: 26},
'condition': {0: 'typhoon', 1: 'Rain', 2: 'Rain', 3: 'Cloudy', 4: 'Sunny', 5: 'Sunny', 6: 'Sunny'}
}
df= pd.DataFrame(dict)
print(df)10. 데이터 프레임> CSV파일로 변환하기
to_csv("파일경로")
로 데이터 프레임을 csv파일로 변환한다.
df.to_csv("new_Dict.csv")new_Dict.csv 파일이 생겼다!

csv 파일 형식이다.

'파이썬 > 파이썬(python) 중급' 카테고리의 다른 글
| [25-4 파이썬] addshape(), onscreenclick(), mainloop() (0) | 2022.09.07 |
|---|---|
| [25-3 파이썬] 판다스로 데이터 처리하기(실습: 센트럴파크 다람쥐) (0) | 2022.09.06 |
| [25-1 파이썬] csv 내장라이브러리로 CSV파일 다루기 (0) | 2022.09.04 |
| [24-10 파이썬] 메일머지 구현하기 (0) | 2022.09.04 |
| [24-9 파이썬] strip() (0) | 2022.09.04 |