뉴욕 센트럴파크의 다람쥐 데이트를
판다스를 가지고 분석해보자!
아래의 사이트로 가면, 센트럴파크의 다람쥐에 대한 정보를 수집한 데이터셋을 얻을 수 있다.
https://data.cityofnewyork.us/Environment/2018-Central-Park-Squirrel-Census-Squirrel-Data/vfnx-vebw
2018 Central Park Squirrel Census - Squirrel Data | NYC Open Data
data.cityofnewyork.us
이 데이터는 2022년 5월까지 업데이트 된 것으로
공식 제목은 2018 central park squirrel census,
2018년 센트럴 파크 다람쥐 조사이다.

컬러맵을 보면, 다람쥐의 분포도를 여러 색깔의 작은 점으로 표시했다.

작은 점에 마우스를 가져다 대면, 몇 마리의 다람쥐인지, 색깔은 어떤지 등
다람쥐에 대한 정보를 준다.

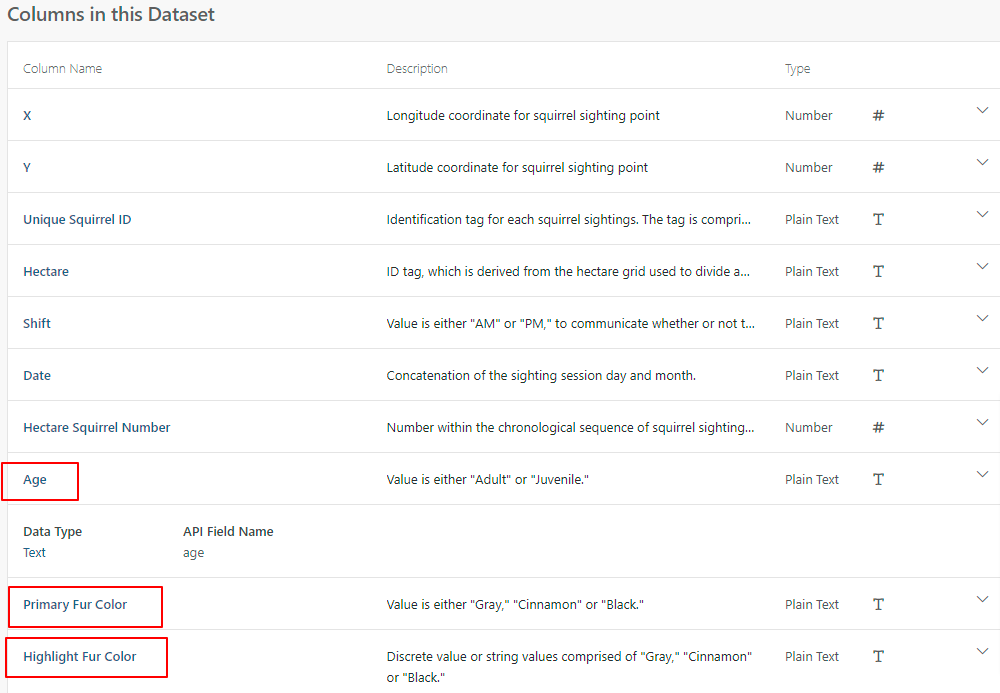
이 데이터셋의 열을 보면,
나이, 주된 털 색깔, 강조된 털 색깔 등이 있다.
데이터셋을 다운로드 받는다.
export> CSV

데이터를 열어보면, 엄청나게 양이 많은데,
우리가 필요한 것은 Primary Fur Color 이다.

오늘의 미션은 아래와 같다.
센트럴파크에 있는 다람쥐 중, Primary Fur Color grey, red, black의 개체수를 파악하고,
이 데이터로 dataframe을 만든다.
마지막에는 이를 csv로 변환한 파일을 만든다.
지금부터 해결해보자!
1. 판다스를 불러오고, 데이터 프레임을 만든다.
import pandas as pd
data = pd.read_csv("2018_Central_Park_Squirrel_Census_-_Squirrel_Data.csv")
df = pd.DataFrame(data)
print(df)C:\Users\samsung\PycharmProjects\25-2\venv\Scripts\python.exe C:/Users/samsung/PycharmProjects/25-2/main.py
X ... Lat/Long
0 -73.956134 ... POINT (-73.9561344937861 40.7940823884086)
1 -73.968857 ... POINT (-73.9688574691102 40.7837825208444)
2 -73.974281 ... POINT (-73.97428114848522 40.775533619083)
3 -73.959641 ... POINT (-73.9596413903948 40.7903128889029)
4 -73.970268 ... POINT (-73.9702676472613 40.7762126854894)
... ... ... ...
3018 -73.963943 ... POINT (-73.9639431360458 40.7908677445466)
3019 -73.970402 ... POINT (-73.9704015859639 40.7825600069973)
3020 -73.966587 ... POINT (-73.9665871993517 40.7836775064883)
3021 -73.963994 ... POINT (-73.9639941227864 40.7899152327912)
3022 -73.975479 ... POINT (-73.9754794191553 40.7696404489025)
[3023 rows x 31 columns]
2. df에서 Primary Fur Color 열의 값을 확인한다.
총 3023개의 열이 있다.
print(df["Primary Fur Color"])[3023 rows x 31 columns]
0 NaN
1 NaN
2 Gray
3 Gray
4 Gray
...
3018 Gray
3019 Gray
3020 Gray
3021 Gray
3022 Cinnamon
Name: Primary Fur Color, Length: 3023, dtype: object
3. Primary Fur Color 열에서 값이 Gray인 경우가 있는지 불린값으로 출력한다.
print(df["Primary Fur Color"]=="Gray")0 False
1 False
2 True
3 True
4 True
...
3018 True
3019 True
3020 True
3021 True
3022 False
Name: Primary Fur Color, Length: 3023, dtype: bool
4. df에서 primary Fur Color가 Gray인 경우만 출력한다.
df1 = df[df["Primary Fur Color"]=="Gray"]
print(df1) X ... Lat/Long
2 -73.974281 ... POINT (-73.97428114848522 40.775533619083)
3 -73.959641 ... POINT (-73.9596413903948 40.7903128889029)
4 -73.970268 ... POINT (-73.9702676472613 40.7762126854894)
6 -73.954120 ... POINT (-73.9541201789795 40.7931811701082)
7 -73.958269 ... POINT (-73.9582694312289 40.7917367820255)
... ... ... ...
3016 -73.966290 ... POINT (-73.9662895079734 40.7843300758044)
3018 -73.963943 ... POINT (-73.9639431360458 40.7908677445466)
3019 -73.970402 ... POINT (-73.9704015859639 40.7825600069973)
3020 -73.966587 ... POINT (-73.9665871993517 40.7836775064883)
3021 -73.963994 ... POINT (-73.9639941227864 40.7899152327912)
[2473 rows x 31 columns]
5. 총 길이를 구해서 해당 값을 count한다.
count_gray = len(df1)
print(count_gray)2473
6. 나머지 색깔도 똑같이 구한다.
df2 = df[df["Primary Fur Color"]=="Cinnamon"]
df3 = df[df["Primary Fur Color"]=="Black"]
count_cinnamon = len(df2)
count_black = len(df3)
7. dictionary를 구성한다.
data_dict = {
"Fur Color": ["Gray", "Cinnamon", "Black"],
"Count": [count_gray, count_cinnamon, count_black]
}
print(data_dict){'Fur Color': ['Gray', 'Cinnamon', 'Black'], 'Count': [2473, 392, 103]}
8. 데이터 프레임을 만든다.
df = pd.DataFrame(data_dict) Fur Color Count
0 Gray 2473
1 Cinnamon 392
2 Black 103
9. 엑셀파일로 만든다.
df.to_csv("squirrel.csv")

혹은 판다스 메소드를 많이 사용하여,
중간 과정을 이렇게 바꿀 수도 있다.
dropna()
dropna() 메소드로 NaN값은 제거한다.
df = df["Primary Fur Color"]
df= df.dropna()
print(df)기본 데이터프레임에서 Primary Fur Color 열만 추출한 다음,
unique()
df가 가지고 있는 고유값을 구한다.
print(df.unique())
['Gray' 'Cinnamon' 'Black']
to_list()
df를 리스트로 변환하여 list 함수인 len()를 써서
df가 총 몇 개의 유효한 값을 가지는지 확인한다.
df_list = df.to_list()
print(len(df_list))2968
count()
Gray, Cinnamon, Black 세 개의 값이 몇개인지 count()함수를 써서 구한다.
a, b, c 세 개의 수를 합치면 위의 2968이 나오면 된다!
a=df_list.count('Gray')
print(a)
b=df_list.count('Cinnamon')
print(b)
c=df_list.count('Black')
print(c)2473
392
103
DataFrame()
to_csv
dataframe = pd.DataFrame({"fur Color": [ 'Gray', 'Cinnamon', 'Black'],
"count": [a, b, c]})
print(dataframe)
dataframe.to_csv("squirrel.csv")
'파이썬 > 파이썬(python) 중급' 카테고리의 다른 글
| [25-5 파이썬] read_csv(), to_list(), textinput(title, prompt), while, with as, if break (0) | 2022.09.11 |
|---|---|
| [25-4 파이썬] addshape(), onscreenclick(), mainloop() (0) | 2022.09.07 |
| [25-2 파이썬] pandas 판다스로 데이터처리하기 (0) | 2022.09.06 |
| [25-1 파이썬] csv 내장라이브러리로 CSV파일 다루기 (0) | 2022.09.04 |
| [24-10 파이썬] 메일머지 구현하기 (0) | 2022.09.04 |