목차
이제까지 linear regression, logistic regression에 대해 공부했다.
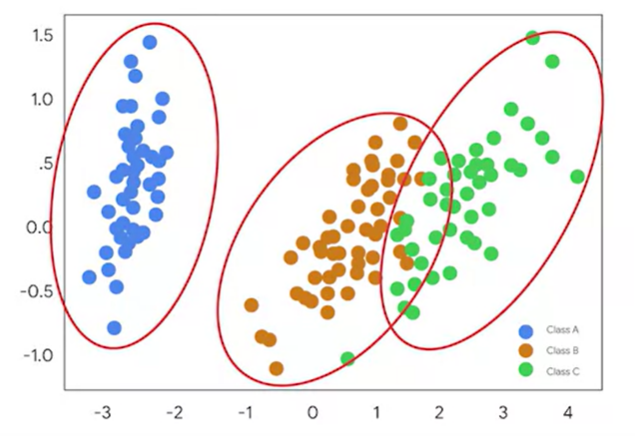
만약 어떤 데이터셋을 주고, 이것을 scatterplot으로 표현했다고 하자.
이러한 데이터셋은 앞서 배운 회귀모델로 처리할 수 있을까?
어렵다.
따라서 다양한 데이터에 적절히 적용할 수 있는 다양한 머신러닝 모델이 필요한 것이다.
Machine Learning
It involves using algorithms and statistical models to tach computer systems to analyze and discover pattern in data.

1. Main types of machine learning
머신러닝 타입은 크게 두 가지로 나뉜다
.
1) Supervised learning
Uses labeled datasets to train algorithms to classify or predict outcomes.
Labeled data: it has been tagged with a label that represents a specific metric, property or class identification.
이미 가지고 있는 정답을 가지고, 미래의 정답을 예측하거나, 분류하는 것을 말한다.
2) Unsupervised learning
Uses algorithms to analyze and cluster unlabeled datasets.
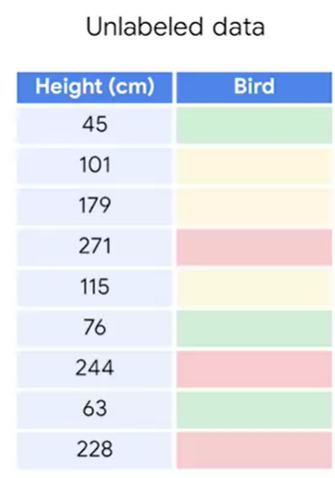
예) 아래의 데이터를 보면 레이블이 없다. 이러한 데이터셋의 경우 X값을 공통 패턴이 있는 것끼리 그룹짓는 것이 Unsupervised model의 목표가 된다.
3) Reinforcement learning
It is often used in robotics and is based on rewarding or punishing a computer's behaviors.
컴퓨터는 강화학습을 통해 배운 규칙에 따라 행동한다. reward는 강화하고 penalty는 최소화 시키는 방식으로 계속적인 학습을 진행한다.
4) Deep learning
Layers of interconnected nodes.
노드는 전층에서 시그널을 받는다. 그 다음 활성화 된다. 그리고 다음 층의 노드로 시그널을 보낸다. 만약 최종층이라면 결과를 도출한다.

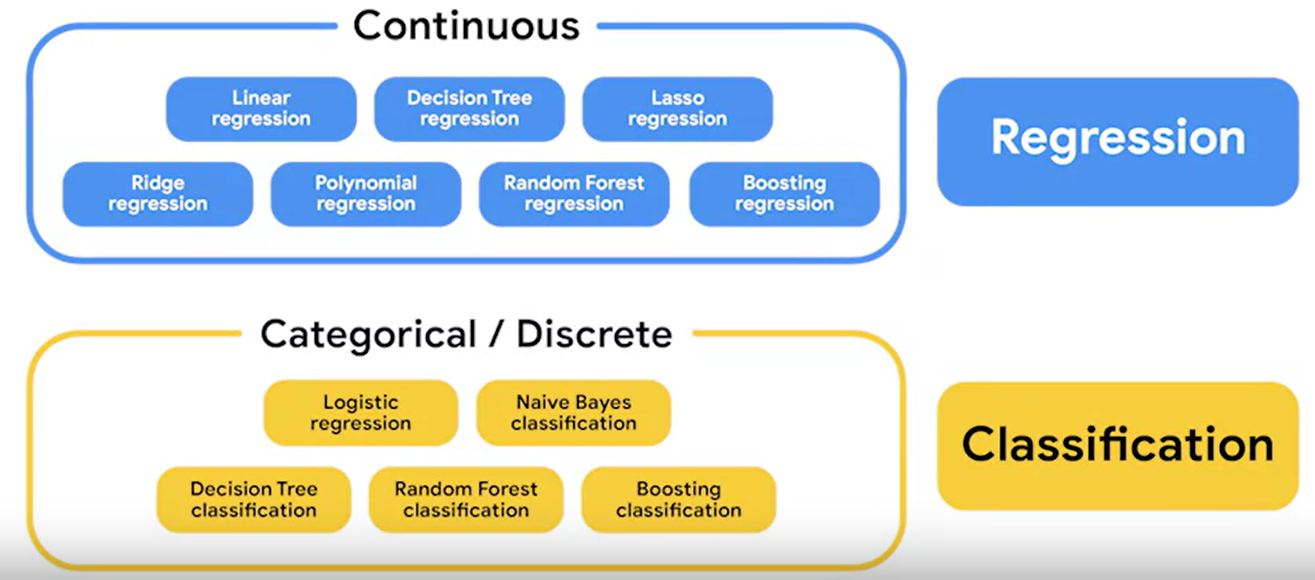
2. Variable types
variable들이 어떤 타입인지 이해하는 것은 적절한 머신러닝 모델의 타입과 평가방법을 결정하는데 너무 중요하다.
1) Continuous : infinite, uncountable
2) Categorical : finite number of groups or categories
3) Discrete : countable number of values between any two values.
ex)
나무의 높이 : Continuous variable ----> 셀수없고, 무한이다
나무의 수: Discrete variable ---> 셀 수 있다
나무의 종류: Categorical variable ---> 그룹지을 수 있다.
3. Recommendation systems
Unsupervised learning techniques that use unlabeled data to offer relevant suggestions to users.
목표: To quantify how similar one thing is to another.
1) Content-based filtering
Comparisons are made based on attributes of content.
만약 음악을 들으면, 그 다음 곡으로 비슷한 음악이 재생된다.
<장점>
- 이해하기 쉽다
- 사용자가 좋아하는 걸로 추천이 된다.
- 다른 사용자에 대한 정보가 필요하지 않다.
- 특정 항목을 비교하는 데 국한되지 않는다. 비슷한 컨텐츠를 다양한 항목에서 매핑한 다음, 사용자가 선택했던 콘텐츠와 가장 가까운 항목을 추천한다.
<단점>
- 과거에 받았던 종류의 컨텐츠만 추천받을 수 있다. 다양성이 낮다.
- 사용자가 선택한 콘텐츠와 유사한 모든 항목을 매핑한다는 것은 거대한 일이다.
- 완전히 다른 컨텐츠 타입은 유사성이 떨어지기 때문에 추천받지 못한다.
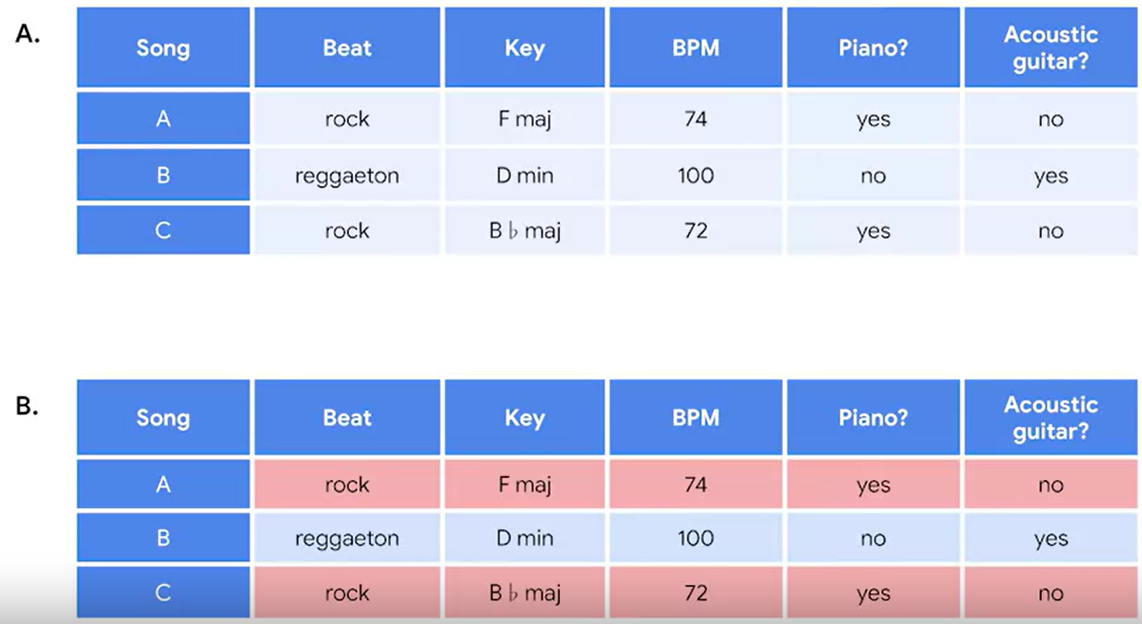
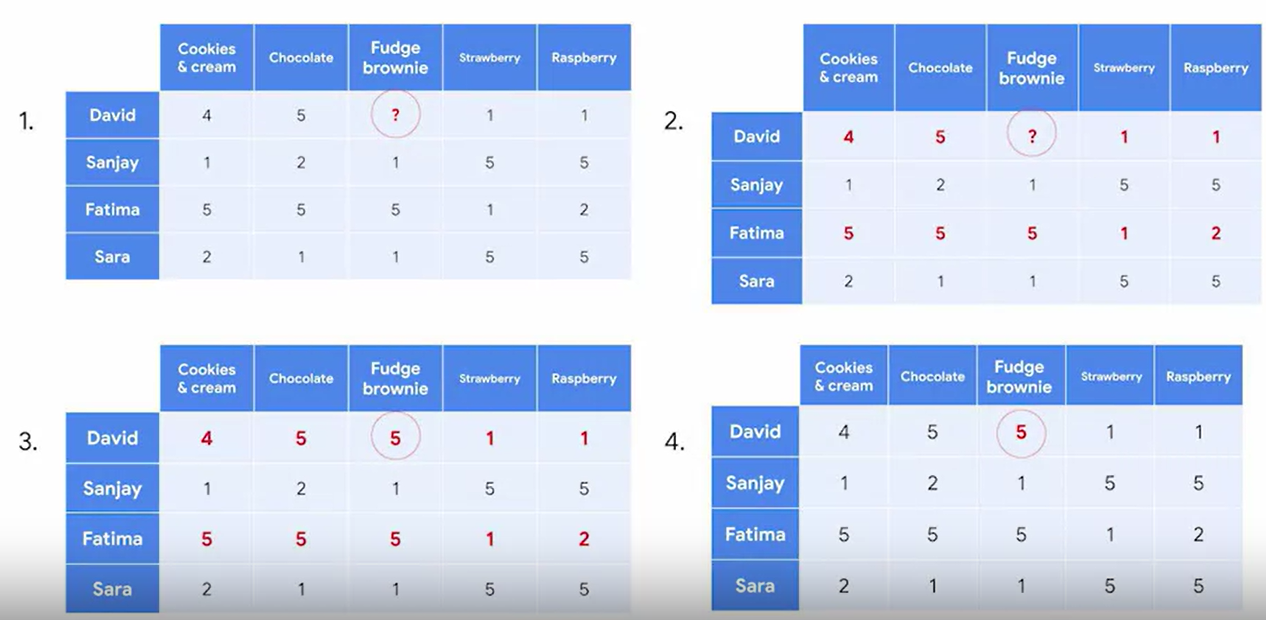
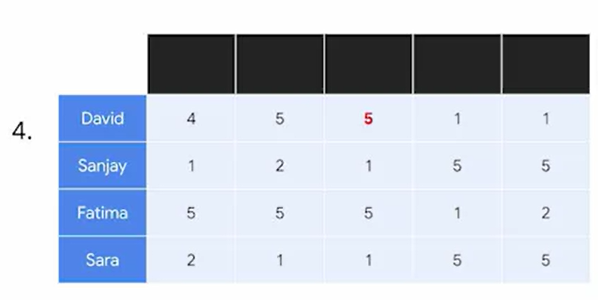
2) Collaborative filtering
Comparisons are made based on who else liked the content
아래의 예시처럼, 데이비드와 파티마가 비슷한 취향을 가지고 있으므로, 나머지 하나도 비슷할 것이라고 생각하는 것이다.
<장점>
- 다양한 콘텐츠 유형에서 추천할 수 있다.
- 데이터의 숨은 연관성을 파악할 수 있다.
- 지루한 수동 매핑이 필요하지 않다.
<단점>
- 많은 데이터가 필요하다.
- 데이터에 missing value를 포함하는 sparse가 많다.
4. Ethics for machine learning
- 데이터가 bias 되었다면, 모델 역시 bias된다.
- 머신러닝을 매우 강력한 도구이기에, 윤리적인 문제를 고려해야 한다.

5. Python
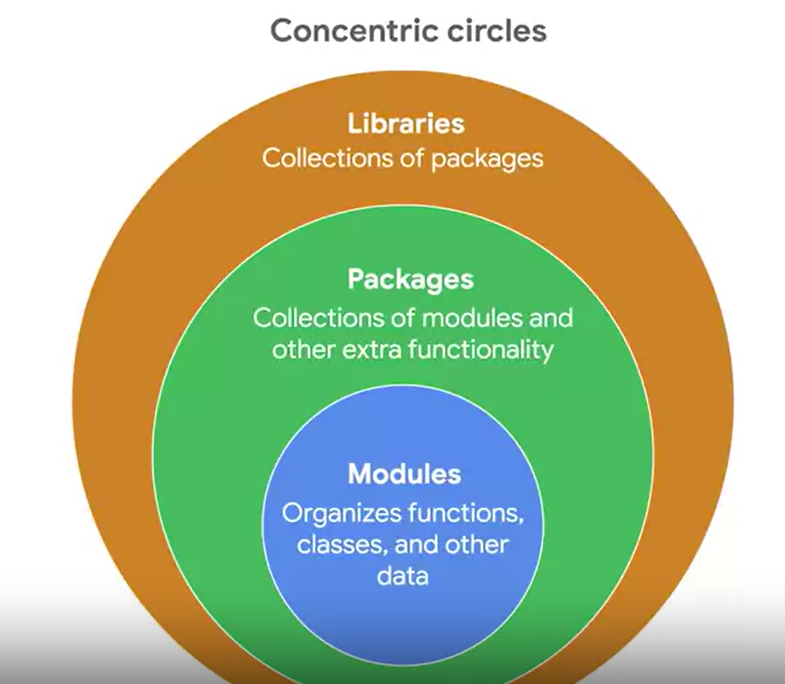
1) Library> Package> Module
2) 유용한 패키지 세 가지
- 연산: pandas, numpy, scipy
- 시각화 : matplotlib, seaborn(focus on statistical), plotly
- 머신러닝: scikit learn