목차
Tree-based learning
A type of supervised machine learning that performs classification and regression tasks.
Desision tree
Flow-chart-like supervised classification model, and a representation of various solutions that are available to solve a given problem, based on the possible outcomes of related choices.
데이터의 어떤 기준을 바탕으로 규칙을 만들어, 학습을 통해 정답을 자동으로 찾아낸다. 트리 기반이며, 가장 효율적인 분류가 되도록 알고리즘을 짠다. 정보균일도라는 룰을 기반으로 하고 있어 알고리즘이 쉽고 직관적이다. 전처리 과정이 심플하다. 단점은 과적합으로 정확도가 떨어질 수 있다.
< 장점>
1) Require no assumptions regarding distribution of data
2) Handles collinearity very easily
3) Often doesn't require data preprocessing

<구성>
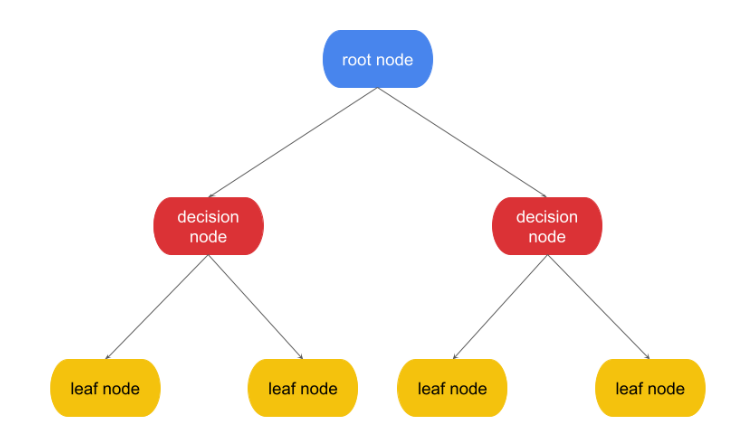
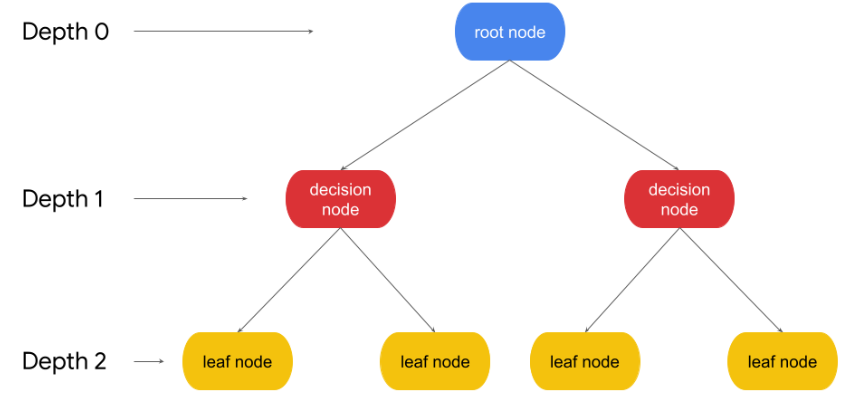
1) Root node
The first node of the tree, where the first decision is made.
최상위 노드
2) Decision node
Nodes of the tree where decisions are made
규칙의 조건이 되는 노드로, 결정의 조건이 된다.
3) leaf node
The nodes where a final prediction is made
자식 노드가 없는, 결정 결과인 마지막 노드로 결정된 클래스 값이다.
4) child node <-> parent node
A node that is pointed to from another node
Python
1. 라이브러리
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# This function displays the splits of the tree
from sklearn.tree import plot_tree
from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix
from sklearn.metrics import recall_score, precision_score, f1_score, accuracy_score
2. 데이터
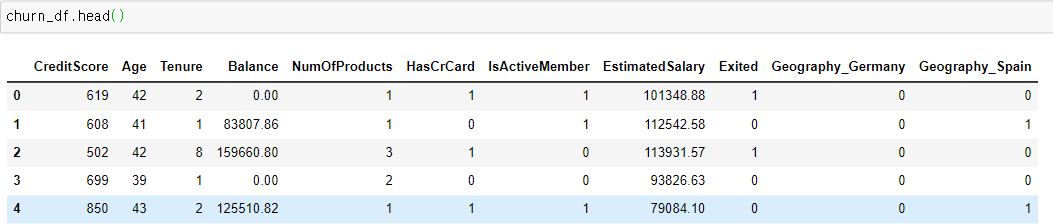
3. EDA
value_counts, mean(), drop(), get_dummies(data, drop_first=True)
4. data split
# target variable
y = churn_df['Exited']
# X (predictor) variables
X = churn_df.copy()
X = X.drop('Exited', axis=1)
# Split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.25, stratify=y,
random_state=42)
5. modeling
# 모델 객체 만들기
decision_tree = DecisionTreeClassifier(random_state=0)
# 훈련
decision_tree.fit(X_train, y_train)
# 예측값
dt_pred = decision_tree.predict(X_test)
6. 평가
print("Accuracy:", "%.3f" % accuracy_score(y_test, dt_pred))
print("Precision:", "%.3f" % precision_score(y_test, dt_pred))
print("Recall:", "%.3f" % recall_score(y_test, dt_pred))
print("F1 Score:", "%.3f" % f1_score(y_test, dt_pred))Accuracy: 0.790
Precision: 0.486
Recall: 0.503
F1 Score: 0.494
7. 혼동행렬
def conf_matrix_plot(model, x_data, y_data):
model_pred = model.predict(x_data)
cm = confusion_matrix(y_data, model_pred, labels=model.classes_)
disp = ConfusionMatrixDisplay(confusion_matrix=cm,
display_labels=model.classes_)
disp.plot(values_format='')
plt.show()
conf_matrix_plot(decision_tree, X_test, y_test)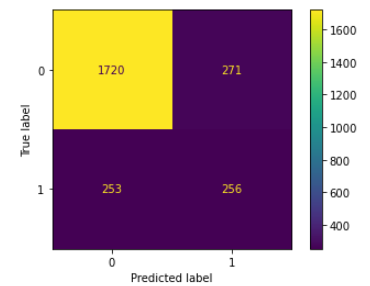
8. 트리 그래프 그리기 plot_tree()
plt.figure(figsize=(15,12))
plot_tree(decision_tree, max_depth=2, fontsize=14, feature_names=X.columns,
class_names={0:'stayed', 1:'churned'}, filled=True);
plt.show()
복잡한 학습 모델은 결국 실제 상황에서 유연하게 대처가 어려워 예측 성능이 떨어진다. 결정트리 모델은 과적합이 발생하기 쉬운 모델이다. 차라리 트리의 크기(max_depth)를 사전에 제한하는 것이 오히려 모델 성능에 도움이 된다.
max_depth
그려지는 최대 깊이를 제한한다. 깊이가 깊어질수록 과적합 가능성이 높아져 결정 트리의 예측 성능이 저하될 우려가 있다.
feature_names: 입력 데이터셋 X의 열 이름이다.
class_names는 클래스 레이블에 해당하는 이름으로 매핑한다.
filled=True는 트리 노드를 주요 클래스에 따라 색으로 표시한다.
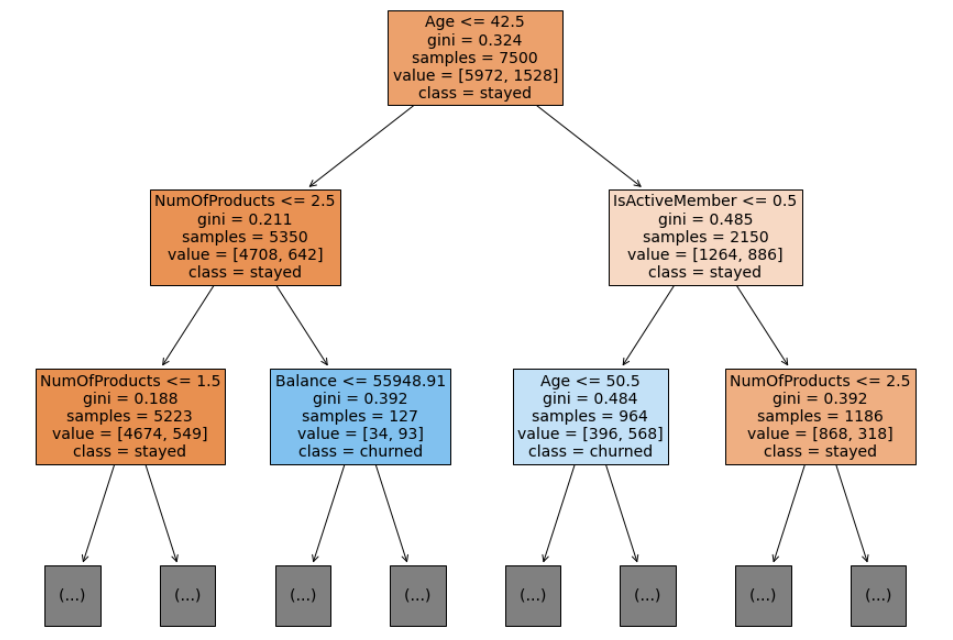

데이터를 분류할 때 최대한 많은 데이터 세트가 해당 분류에 속할 수 있도록 결정 노드의 규칙이 정해진다.
위의 경우에서는 루트노드에서 Age<=42.5 를 기준으로 가지가 나뉜다.
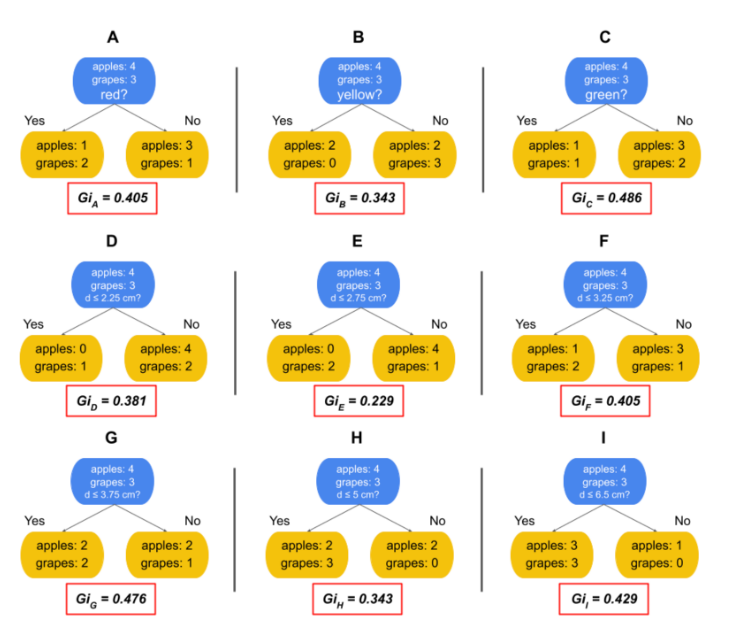
정보균일도
가능한 적은 결정 노드로 높은 예측 정확도를 가지려면 최대한 균일한 데이터 세트를 구성할 수 있도록 트리를 분할해야 한다. 최대한 균일하다는 뜻은 정보균일도가 높다는 뜻이다. 이를 측정하는 대표적인 방법에는 지니계수가 있다.
지니계수
gini는 지니 불순도(Gini impurity)를 나타낸다. 결정트리는 가지를 나눌 때 분순도를 최소화하는 방향으로 데이터를 분할하는데, 지니 불순도는 그 중 하나의 불순도 측정 지표이다.
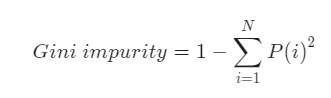
0부터 0.5 사이의 값을 가진다.
0은 해당 노드의 모든 샘플이 동일한 클래스로 구성되어 완벽하게 순수할 때, 즉 불순도 0인 경우
0.5는 노드에 샘플들이 균등하게 분포되어 가장 불순도가 높은 상태를 말한다.

Hyperparameter tuning
Parameters that can be set before the model is trained.
모델 성능을 높이기 위해서 모델을 학습 시키기 전에 하이퍼파라미터 튜닝을 한다. 하이퍼파라미터 튜닝을 통해 오버피팅을 방지하는데 중요한 역할을 한다.
decision tree에서 대표적인 하이퍼파라미터는 Max depth, Min samples leaf이다.
1) Max depth
Defines how long a decision tree can get
루트 노드가 0인데, 가장 먼 노드까지의 깊이를 이야기한다.
너무 복잡한 데이터셋에서 불 필요하게 depth를 길게 가져가서 overfitting을 야기할 필요가 없다.
따라서 max depth를 설정해서 오버피팅의 가능성을 낮춘다.
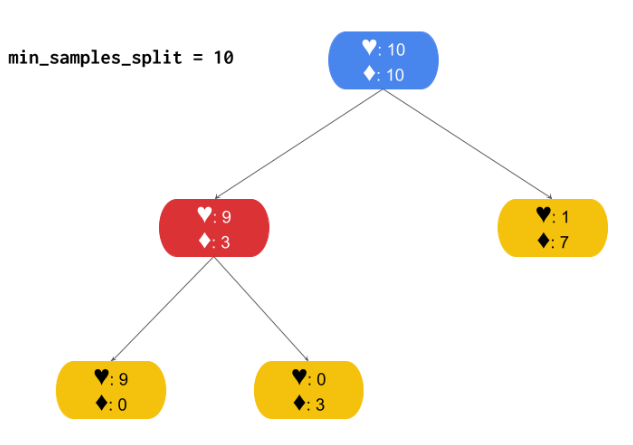
2) Min samples leaf
Defines the minimum number of samples for a leaf node.
leaf 노드의 샘플들의 개수가 중요하다. 리프노드가 가져야 하는 최소 샘플 수를 지정한다. 최소 min 이상이어야 한다는 뜻이다. 너무 작은 값은 오버피팅을 유발한다.
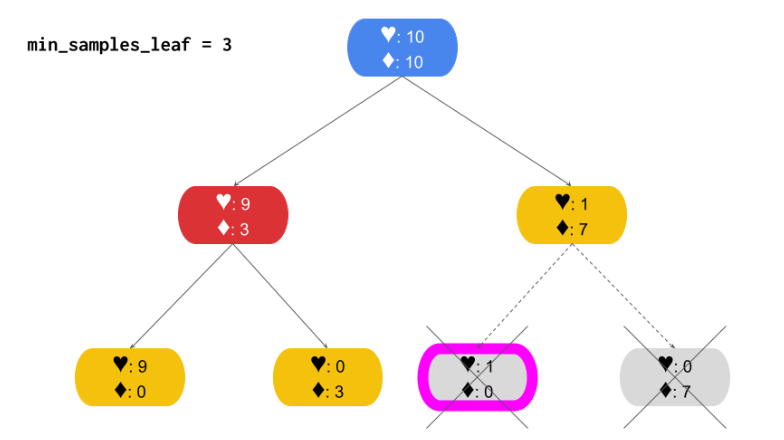
3) Min samples split
it is the minimum number of samples that a node must have for it to split into more nodes.
노드를 분할 하기 위해 필요한 최소 샘플 수이다. 분할 하기 전이 포인트이다. 분할 하기 전에 가져야 하는 최소 샘플 수를 말한다. 너무 크게 설정하면 언더피팅을 유발할 수 있다.
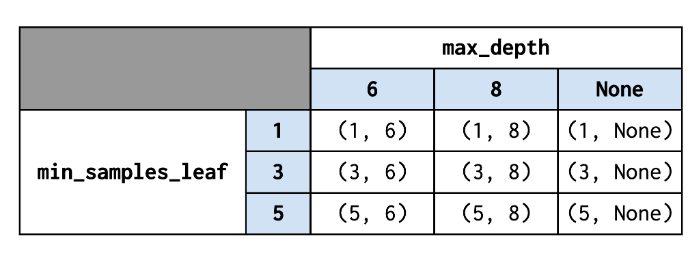
GridSearch
A tool to confirm that a model achieves its intended purpose by systematically hecking every combination of hyperparameters to identify which set produces the best results based on the selected metric.
하이퍼파라미터는 사람이 조절하는 것이다. 하지만 최적의 하이퍼파라미터를 찾을 수 있게 도와주는 모듈이 있다. 바로 gridsearch이다. 가능한 조합을 계산하여 가장 좋은 하이퍼파라미터를 알려준다.
1) 라이브러리, 모델 만들기
from sklearn.model_selection import GridSearchCV
tuned_decision_tree = DecisionTreeClassifier(random_state = 42)
2) 하이퍼파라미터
tree_para = {'max_depth':[4,5,6,7,8,9,10,11,12,15,20,30,40,50],
'min_samples_leaf': [2, 5, 10, 20, 50]}
scoring = {'accuracy', 'precision', 'recall', 'f1'}
clf = GridSearchCV(tuned_decision_tree,
tree_para,
scoring = scoring,
cv=5,
refit="f1")classifier: tuned_decision_tree
hyperparameter: tree_para
scoring metrics: scoring
number of cross-validation folds : cv
the scoring metric that you want gridsearch to use when it selects the best model. : refit
3) 학습
clf.fit(X_train, y_train)
4) 베스트 파라미터
clf.best_estimator_
5) 평가
print("Best Avg. Validation Score: ", "%.4f" % clf.best_score_)Best Avg. Validation Score: 0.5607
def make_results(model_name, model_object):
cv_results = pd.DataFrame(model_object.cv_results_)
# Isolate the row of the df with the max(mean f1 score)
best_estimator_results = cv_results.iloc[cv_results['mean_test_f1'].idxmax(), :]
# Extract accuracy, precision, recall, and f1 score from that row
f1 = best_estimator_results.mean_test_f1
recall = best_estimator_results.mean_test_recall
precision = best_estimator_results.mean_test_precision
accuracy = best_estimator_results.mean_test_accuracy
# Create table of results
table = pd.DataFrame()
table = table.append({'Model': model_name,
'F1': f1,
'Recall': recall,
'Precision': precision,
'Accuracy': accuracy
},
ignore_index=True
)
return table
result_table = make_results("Tuned Decision Tree", clf)
result_table.to_csv("Results.csv")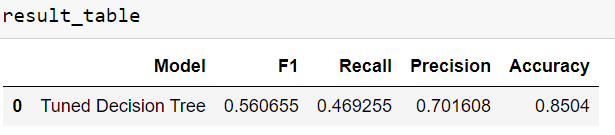
Model validation
하이퍼파라미터까지 결정했다. 그런데 이 하이퍼파라미터가 모델에 적합한지 어떻게 검증할 수 있을까? 우리는 데이터셋을 트레인과 테스트로 나누어놨지만, 하이퍼파라미터 검증을 위해 테스트셋을 사용할 수 없다. 이때 필요한 것이 validation set이다. model을 validation할 수 있는 방법에는 2가지가 있다.
1) standard validation
The set of processes and activities intended to verify that models are performing as expected.
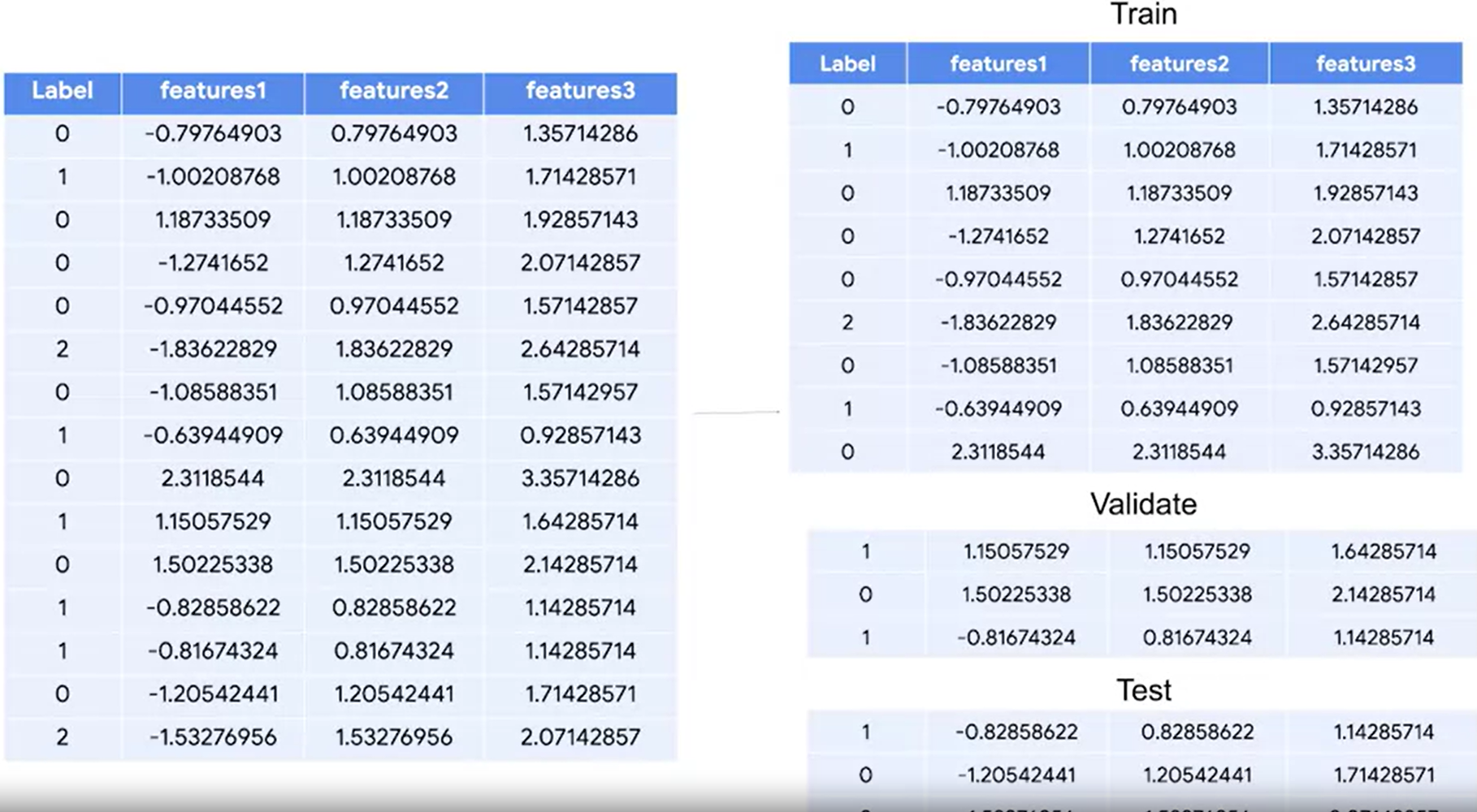
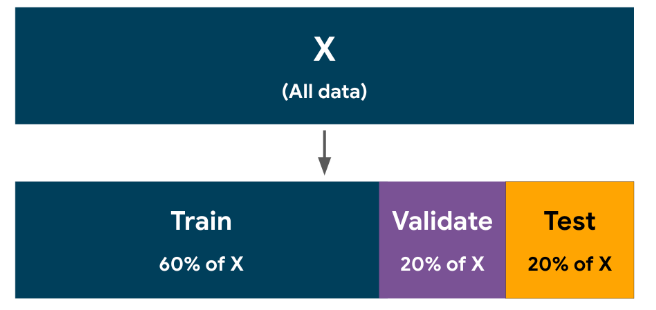
기존에는 데이터셋을 train과 test로 분리했다면, 이번에는 validate까지 포함해서 세 가지로 분리한다.
2) Cross-validation 교차검증
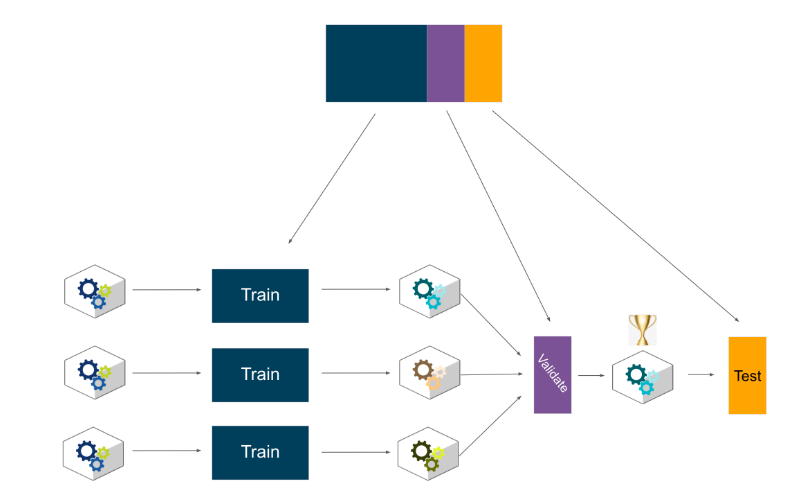
A process that uses different portions of the data to test and train a model on different iteration
기존의 학습데이터, 시험데이터로 나누는 것 역시 과적합의 위험에서 벗어나기 힘들다. 좀더 높은 성능을 발휘할 수 있도록 교차 검증을 이용해 더 다양한 학습과 평가를 수행하게 한다. 예를 들어, 이전의 시험데이터가 수능이었다면, 교차검증은 여러 번의 모의고사를 치루는 것이다. 더 다양한 학습과 평가를 할 수 있다.
<방법>
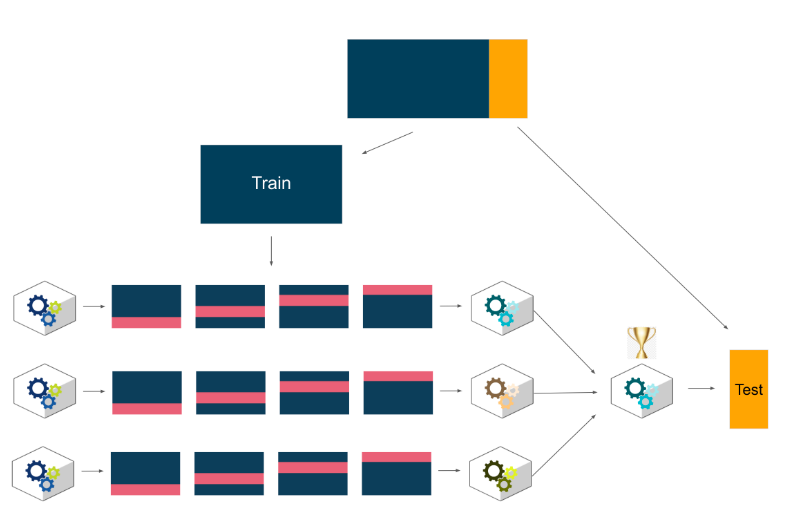
K-fold
기존처럼 데이터셋을 train, test 셋으로 나눠놓고 train을 가지고 5-fold로 나눈다.
아래의 5개의 fold를 가지고 평가를 한 뒤에 이에 대한 평균값을 내어 평가 지표로 삼는다.
데이터 양이 작을 때 cross- validation을 쓰는 것이 유리하고, 데이터 양이 많다면 standard validation을 쓰는 것을 추천한다.

stratified k-fold
imbalanced한 분포를 가진 레이블 데이터셋에서 쓰이는 k fold방식이다. 불균형한 분포도를 가진 레이블 데이터 집합은 데이터셋을 트레인, 테스트, 벨리데이션으로 나눌 때 레이블이 골고루 나누어지지 않을 수 있다. strafied k-fold는 원본 데이터의 레이블 분포를 먼저 고려한 뒤, 이 분포와 동일하게 학습과 검증 데이터 세트에서 레이블을 분배한다.