목차
ensemble learning
Aggregating their outputs to make a prediction
여러 개의 분류기를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법. 다양한 분류기의 예측 결과를 결합하는 것이 단일 분류기보다 신뢰성이 높은 예측값을 얻을 수 있다.
1. Voting
서로 다른 알고리즘을 가진 부류기를 결합
1) Hard Voting
다수결의 원칙을 따른다. 예측한 결과값 중 다수의 분류기가 결정한 예측값을 최종 voting결과값으로 선정한다.
2) Soft Voting
분류기들의 레이블 값 결정 확률을 모두 더하고 이를 평균해서, 확률이 가장 높은 레이블 값을 최종 보팅 결괏값으로 선정한다.
2. bagging= bootstrap aggregating
각각의 분류기가 같은 유형의 알고리즘이지만, 데이터 샘플링이 서로 다르게 하여 학습한 후, 보팅을 수행한다.
1) Base learner
Each individual model that comprises an ensemble.
앙상블을 이루는 각각의 분류기
- weak learner(예측값이 좋지 않은 경우),
- strong learner(예측값이 의미있는 경우)
2) Bootstraping
개별 classifier에게 데이터를 샘플링해서 추출하는 방식을 부트스트래핑 분할 방식이라고 한다. 개별 분류기가 부트스트래핑 방식으로 중첩을 허용하여 데이터를 샘플링해서, 학습하고, 예측을 수행한 결과를 보팅해서 최종 예측을 하는 방식을 배깅이라고 한다.
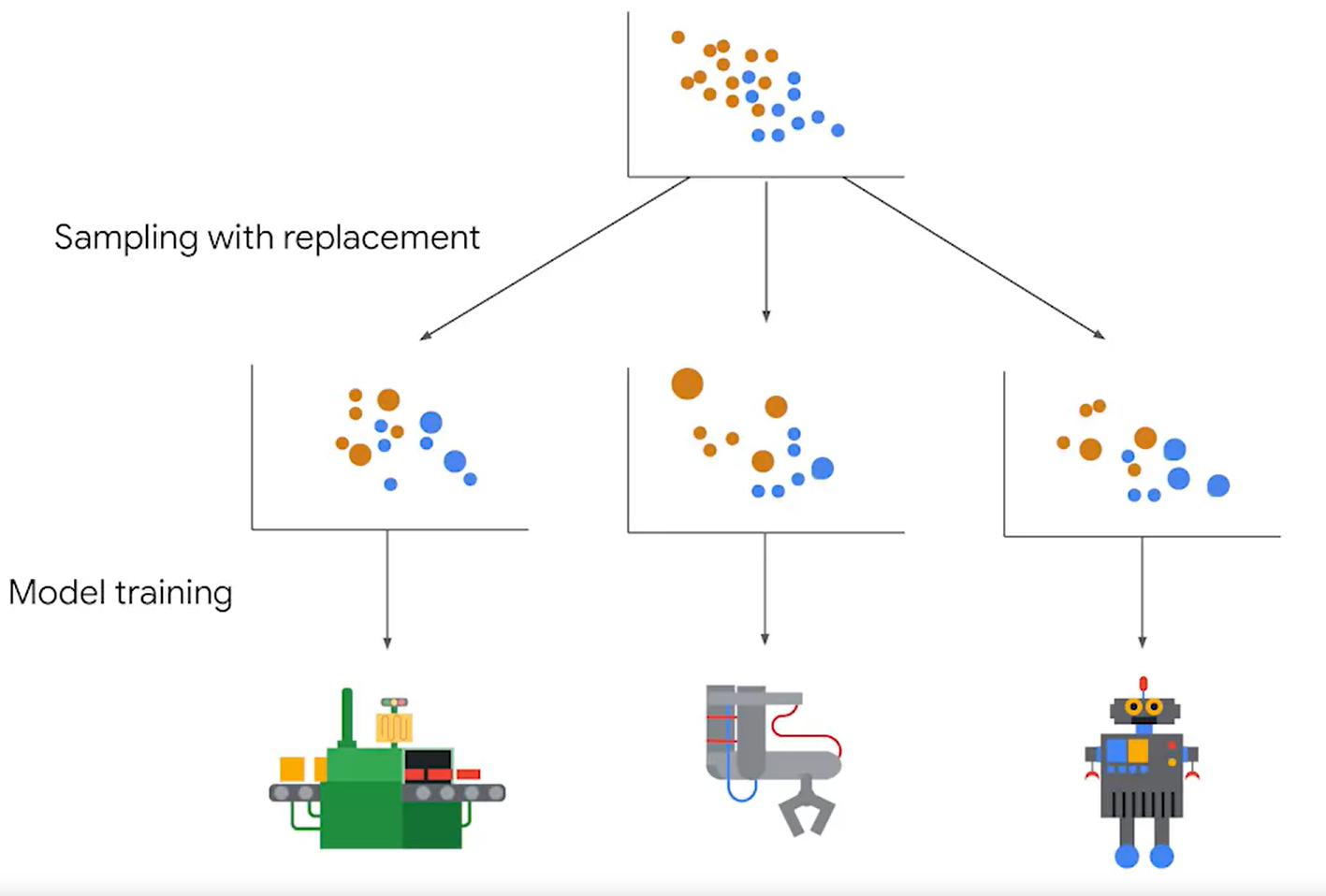

3) Random forest
Ensemble of decision trees trained on bootstrapped data with randomly selected features.
배깅의 대표적인 알고리즘이 랜덤포레스트이다. 높은 수행 속도, 높은 예측 성능을 보인다. 랜덤 포레스트는 여러 개의 Decision tree 결정 트리 분류기가 전체 데이터를 배깅 방식으로 샘플링해 개별적으로 학습을 수행한 뒤 결과를 낸다. 마지막에 모든 분류기의 결과를 기반으로 보팅을 적용해서 전체 예측 결정을 한다.
이전에도 말했듯이 decision tree는 test에 대해서 높은 성능을 발휘하지만 overfitting의 가능성이 있다고 했다. 그런데 랜덤포레스트를 이용하면 이런 단점을 상쇄할 수 있다. 왜냐면 train 되는 데이터가 모두 다르기 때문이다.
4) Random forest hyperparameter
<Decision Tree hyperparameter>
- max_depth
- min_samples_leaf
- min_samples_split
+ <Ensembles hyperparameter>
- max_features : Specifies the number of features that each tree randomly selects during training. 피처 선택
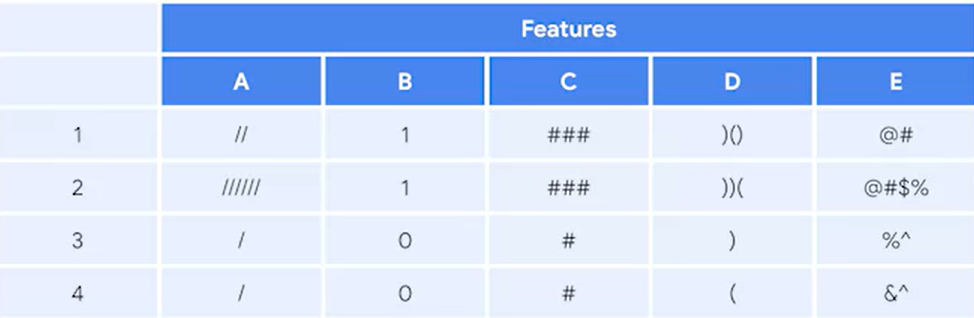
--> 피처가 5개이다. 만약 max_features=3라고 하면 아래와 같이 base learner의 샘플 데이터가 랜덤하게 뽑아진다.

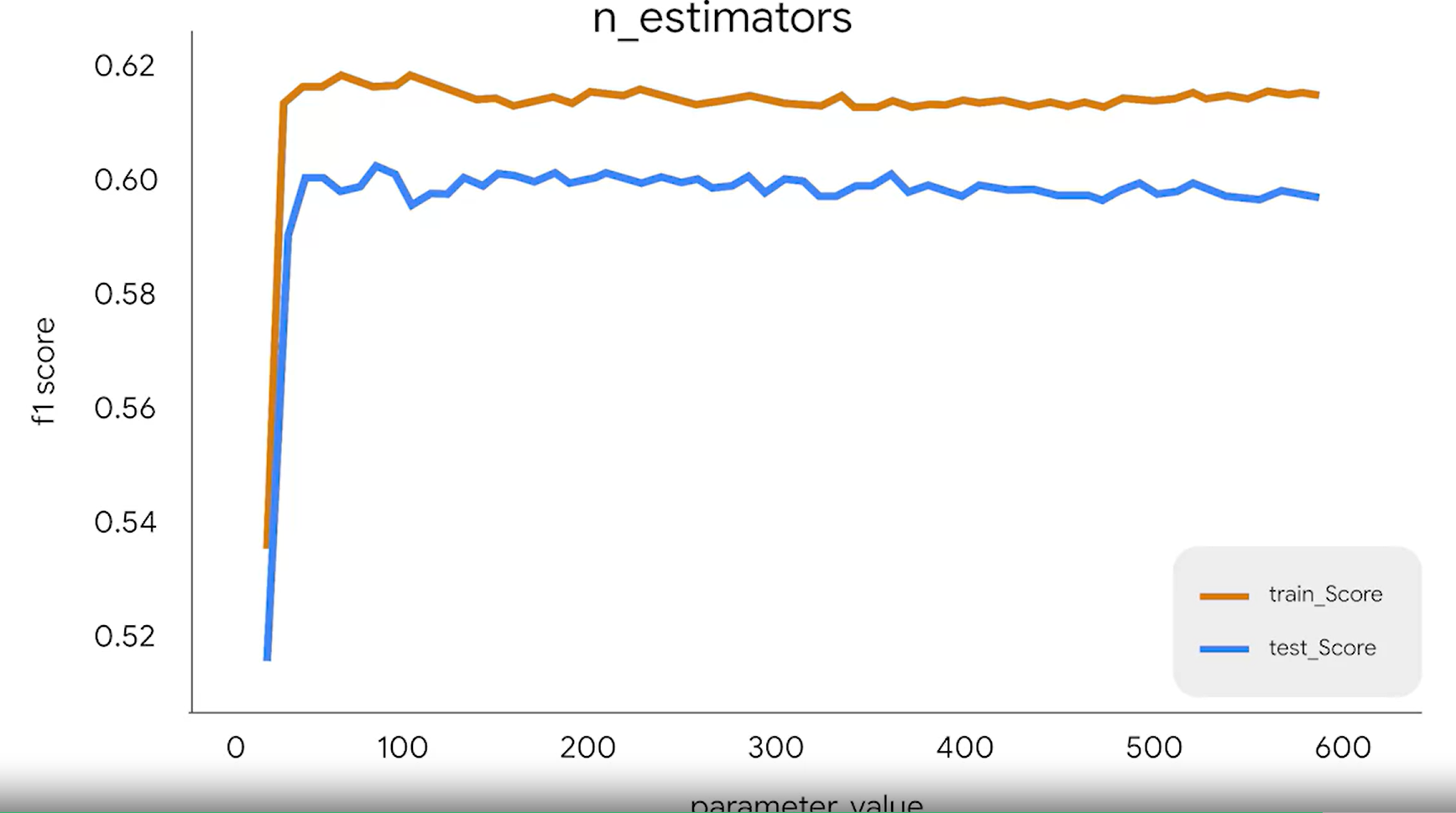
- n_estimators 결정 트리 개수
Specifies the number of trees your model will in its ensemble.
보통 base learner가 많아지면 일정 개수까지는 성능이 좋아지는데, 어떤 포인트를 지나면 더이상 성능 개선이 안된다. 왜냐면 새로 만들어지는 estimator가 다른 것들과 거의 유사해서 크게 도움이 안되기 때문이다.
Python
1. 라이브러리
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
pd.set_option('display.max_columns', None)
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score,\
f1_score, confusion_matrix, ConfusionMatrixDisplay
from sklearn.ensemble import RandomForestClassifier
2. 데이터
3. 데이터 분할
y = churn_df2["Exited"]
X = churn_df2.copy()
X = X.drop("Exited", axis = 1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, stratify=y, random_state=42)
4. %%time
A magic command that gives you the runtime of the cell it's entered in
파이썬에서 이미 내장된 명령어로 간단하게 선언할 수 있으며 Magic commands라고 부른다.
% 또는 %%로 시작한다.
5. 모델링
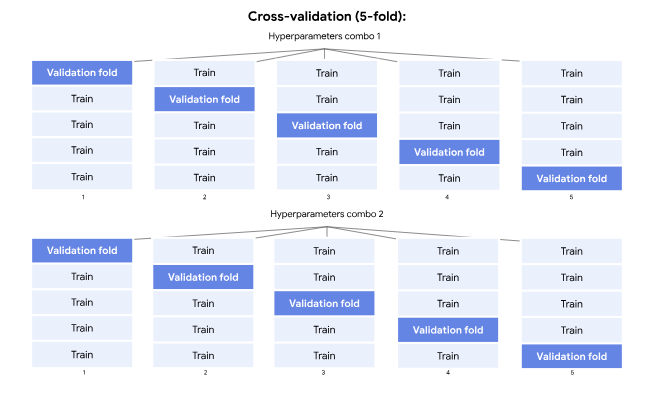
Cross-validation: 5개의 fold로 나눈다.
%%time
rf = RandomForestClassifier(random_state=0)
cv_params = {'max_depth': [2,3,4,5, None],
'min_samples_leaf': [1,2,3],
'min_samples_split': [2,3,4],
'max_features': [2,3,4],
'n_estimators': [75, 100, 125, 150]
}
scoring = {'accuracy', 'precision', 'recall', 'f1'}
rf_cv = GridSearchCV(rf, cv_params, scoring=scoring, cv=5, refit='f1')
rf_cv.fit(X_train, y_train)refit= f1이라는 의미는 최종 estimator을 고를 때, 5개의 교차검증 f1 평균이 가장 높은 것이다.
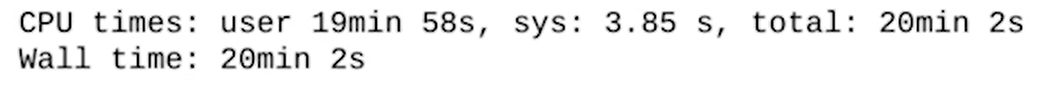
GridSearchCV를 사용할 경우 run time이 많이 걸린다. 여기서는 20분 정도가 걸렸다.
6. pickle
# This module lets us save our models once we fit them.
import picklepickle은 파이썬 모듈로, 객체를 serialize(직렬화), deserialize(역직렬화)하는 기능을 제공한다.
주요 용도는 모델을 저장하거나 나중에 로딩하여 재사용할 수 있도록 한다. 데이터를 파일로 저장하여 데이터 로딩시간을 절약하는 용도로 사용할 수 있다. 결국 시간을 절약할 수 있게 해준다.
최적의 하이퍼파라미터를 찾는 과정은 시간이 굉장히 오래 걸리는데 pickle이 이 시간을 줄여준다.
한 번 모델을 훈련했다면, 이 모델을 파일로 저장해두는 것이다!
pickle is a tool that saves the fit model object to a specified location, then quickly reads it back in. It also allows you to use models that were fit somewhere else, without having to train them yourself.
과정을 살펴보자.
<저장>
# 저장 경로
path = '/home/jovyan/work/'
# 어떤 모델을 저장할 것인지 고른다
with open(path+'rf_cv_model.pickle', 'wb') as to_write:
pickle.dump(rf_cv, to_write)wb 쓴다.
dump ---> rf_cv라는 모델을 해당 위치의 파일로 던진다=저장한다.
<로드>
with open(path + 'rf_cv_model.pickle', 'rb') as to_read:
rf_cv = pickle.load(to_read)rb 읽는다.
load 불러온다.
7. best_params_
rf_cv.best_params_{'max_depth': None,
'max_features': 4,
'min_samples_leaf': 2,
'min_samples_split': 2,
'n_estimators': 125}
8. best_score_
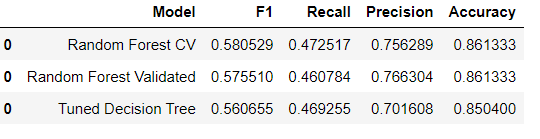
rf_cv.best_score_0.580528563620339
9. 평가

Python2
이번에는 Separate validation set 방법으로 교차검증을 수행해보자.
1. 데이터분할
trainset에서 train할 데이터와 validation할 데이터를 나눈다.
# Create separate validation data
X_tr, X_val, y_tr, y_val = train_test_split(X_train, y_train, test_size=0.2,
stratify=y_train, random_state=10)
X_train.index에서 X_val이면 0을 X_tr이면 -1이라는 인덱스를 부여한다.
split_index = [0 if x in X_val.index else -1 for x in X_train.index]
2. 라이브러리
from sklearn.model_selection import PredefinedSplitPredefinedSplit는 싸이킷런에서 제공하는 데이터분할 전략 중 하나이다. 주로 교차검증 시나리오에서 사용되며, 특정한 분할을 사용하여 데이터셋을 분할하고자 할 때 유용하다.
교차검증의 대표적인 방법은 k-fold 또는 stratified k-fold이다. 그러나 때로는 데이터를 이미 정의된 방식으로 분할해야 하는 경우가 있다. 이런 경우 PredefinedSplit을 사용한다.
3. 모델링
rf = RandomForestClassifier(random_state=0)
cv_params = {'max_depth': [2,3,4,5, None],
'min_samples_leaf': [1,2,3],
'min_samples_split': [2,3,4],
'max_features': [2,3,4],
'n_estimators': [75, 100, 125, 150]
}
scoring = {'accuracy', 'precision', 'recall', 'f1'}
custom_split = PredefinedSplit(split_index)
rf_val = GridSearchCV(rf, cv_params, scoring=scoring, cv=custom_split, refit='f1')
4. 교차검증 시간
이 경우에는 학습 시간이 이전의 1/5로 줄어드는데, 그 이유는 별도의 검증 집합을 사용하기 때문이다. 각 앙상블은 새로운 훈련 집합에서 학습하고 검증 집합에서 검증한다. 하이퍼파라미터의 조합에 대해 1회만 발생하기 때문에 시간이 기존의 cross-validation에서 k-fold를 5로 했을 때보다, 1/5밖에 시간이 걸리지 않는다.
ex) 1-10개의 데이터셋
<Cross-validation>
| validation | train |
| 1,2 | 3~10 |
| 2,3 | 1, 4~10 |
| 3,4 | 1~2, 5~10 |
| 4,5 | 1~3, 6~10 |
| 5,6 | 1~4, 7~10 |
<Separate validation set>
| validation | train |
| 1,2 | 3-10 |
5. 학습
rf_val.fit(X_train, y_train)
6. 피클
with open(path+'rf_val_model.pickle', 'wb') as to_write:
pickle.dump(rf_val, to_write)
with open(path+'rf_val_model.pickle', 'rb') as to_read:
rf_val = pickle.load(to_read)
7. best_params_
rf_val.best_params_{'max_depth': None,
'max_features': 4,
'min_samples_leaf': 1,
'min_samples_split': 3,
'n_estimators': 150}
8. 결과