목차
DBSCAN
Density based Spatial Clustering of Applications with Noise
밀도 기반 군집화의 대표 알고리즘으로 데이터 분포가 기하학적으로 복잡한 데이터 세트에 효과적이다.
높은 밀도의 데이터 포인트의 군집을 형성하고, 밀도가 낮은 지역은 노이즈로 처리한다.
입실론과 MinPts를 사용한다.
★ 입실론: 주변 영역의 반경
★ Min Pts: 해당 영역 내에 존재하는 최소 데이터 포인트 수
클러스터 개수를 지정할 필요 없이, 알고리즘이 자동 결정함.

Evaluation
clustering에서 군집이 잘 만들어졌는지 보기 위해 시각화 작업을 했다. 2차원이나 3차원일 때는 가능하다. 하지만 n차원으로 넘어가면, 쉽지 않아진다. 따라서 다른 방법으로 군집이 잘 되었는지 평가할 필요가 있다.

회귀 모델에서는 label이 있었기 때문에 결정계수, MSE, ROC, Precision, Recall 등으로 모델 평가가 가능했지만, 군집 모델은 label이 없는 unsupervised 이기 때문에 이런 평가 방법이 불가능하다.
좋은 군집화 모델은 보편적으로 어떤 것일까?
다른 군집 간에는 거리가 멀고, 군집 내에서는 거리가 가까운 경우이다.
1) Inertia
Sum of the squared distance between each observation and its nearest centroid.
데이터 포인트들과 centroid의 거리를 최소화하는 것을 목표로 한다. inertia를 최소화하도록 중심을 이동시키며, 이를 반복하여 최적의 클러스터링 결과를 찾는다. 따라서 inertia가 작을수록 데이터포인트들이 클러스터의 중심과 가까이 모여있으며, 클러스터링이 좋다고 평가할 수 있다. 다시 말해, inertia가 가장 낮은 k를 선택하면 데이터를 잘 표현하는 적절한 클러스터링 결과를 얻을 수 있다. 0과 가장 가까울 수록 좋다.
다만 K가 많아질 수록 inertia의 값은 낮아지지만, 그것은 크게 의미가 없다. 꺾이는 부분, 엘보 부분의 지점(elbow curve)을 선택하면 된다. 아래의 그래프에서는 3이 된다.

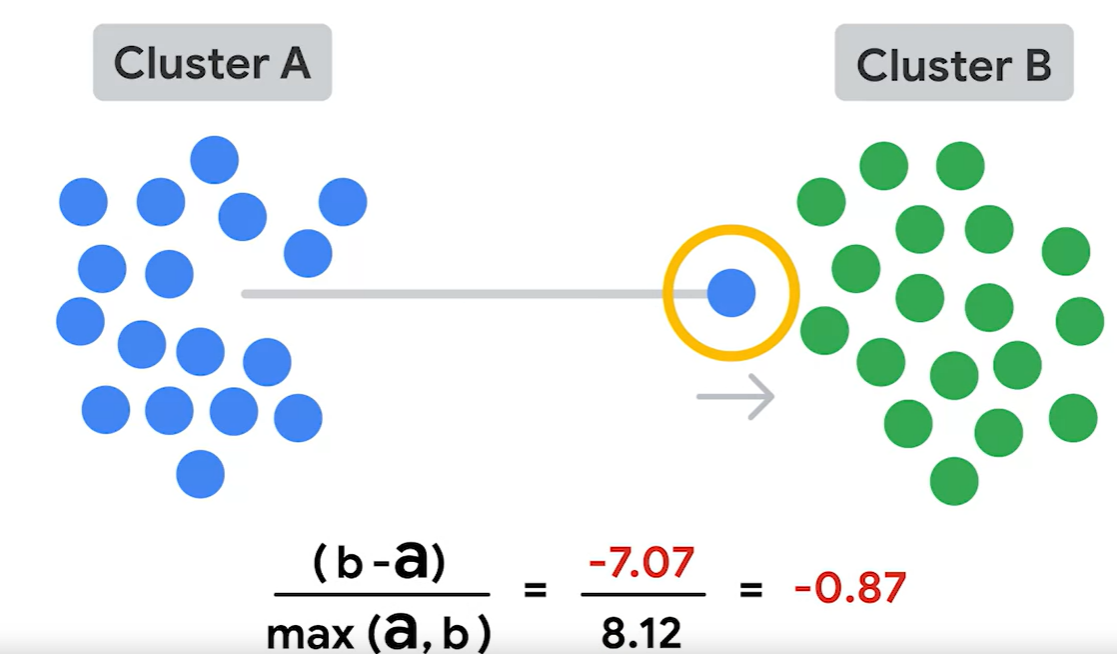
2) Silhouette score
The mean of the silhouette coefficients of all the observations in the model
실루엣 분석은 각 군집 간의 거리가 얼마나 효율적으로 분리돼 있늕를 나타낸다. 이 말은 다른 군집과의 거리는 멀고, 동일 군집 내의 데이터는 가깝게 뭉쳐있다는 뜻이다.
★ 실루엣 계수(silhouette coefficient)====s-->를 기반으로 분석한다.

b: 다른 군집에 있는 데이터 포인트와의 거리를 평균한 값
a: 같은 군집 내 있는 데이터 포인트와의 거리를 평균한 값
-1<s<1


Python
1. 라이브러리
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_blobs
import seaborn as sns
2. 가상 데이터 만들기
1) default_rng()
np.random.default_rng(seed=40)np.random은 넘파이의 하위모듈로서 난수를 생성하는 함수를 제공한다.
default_rng() 함수는 시드가 40인 난수 생성기 객체를 만든다.
2) integers(low, high)
centers= rng.integers(low=3, high=7)integers() 함수는 넘파이 라이브러리의 난수 생성기를 이용해서 low~high사이의 난수 정수를 생성하는 코드이다.
low는 포함, high는 포함하지 않는다. 다시 말해 이상, 미만의 조건이 된다.
위의 경우에는 3~6 사이의 정수를 생성한다는 의미이다.
3) make_blobs()
X, y = make_blobs(n_samples=1000, n_features=6, centers=centers, random_state=42)n_samples: 샘플의 총 개수
n_features: feature=column의 개수
center: 클러스터의 중심 위치
random_state: 난수 발생을 위한 시드값, 동일한 시드라면 항상 같은 데이터셋을 생성한다.
make_blobs: X에는 특성 배열이, y에는 label이 저장된다.
4) pd.DataFrame()
X = pd.DataFrame(X)
3. Scaling
K means로 cluster 모델을 만들 것이다. K means는 거리 기반으로 최종 centroid를 결정한다. 수학적 계산을 해야하기에 데이터를 scaling하는 작업이 반드시 필요하다. sclaer에는 standardScaler, MinMaxScaler, Normalizer 등이 있다.
1) StandardScaler()
이번에는 사이킷런의 StandardScaler을 이용할 것이다.

2) fit_transform()
X_scaled = StandardScaler().fit_transform(X)
X_scaled[:2,:]
4. 모델링
kmeans3 = KMeans(n_clusters=3, random_state=42)
kmeans3.fit(X_scaled)kmean3.labels_
kmeans3.inertia_
kmean3.labels_1748.1488703079513
5. 평가
1) inertia
num_clusters = [i for i in range(2, 11)]
def kmeans_inertia(num_clusters, x_vals):
inertia = []
for num in num_clusters:
kms = KMeans(n_clusters=num, random_state=42)
kms.fit(x_vals)
inertia.append(kms.inertia_)
return inertia
inertia = kmeans_inertia(num_clusters, X_scaled)cluster이 2개서부터 10개까지 개수일 때 inertia값이 얼마인지?
목표는 최소가 되는 것이 좋음.
[3090.3260348468534,
1748.1488703079513,
863.1663243212965,
239.65434758718428,
230.04809652569242,
221.84910615776585,
214.924430018772,
206.49351159542385,
201.31356585907992]
★ 시각화해보자.
엘보지점인 5가 적절한 cluster개수인 것으로 보인다.
plot = sns.lineplot(x=num_clusters, y=inertia)
plot.set_xlabel("Number of clusters");
plot.set_ylabel("Inertia");
2) silhouette score
각 군집별로 실루엣 계수의 합의 평균이 실루엣점수이다.
kmeans3_sil_score = silhouette_score(X_scaled, kmeans3.labels_)0.5815196371994135def kmeans_sil(num_clusters, x_vals):
sil_score = []
for num in num_clusters:
kms = KMeans(n_clusters=num, random_state=42)
kms.fit(x_vals)
sil_score.append(silhouette_score(x_vals, kms.labels_))
return sil_score
sil_score = kmeans_sil(num_clusters, X_scaled)[0.4792051309087744,
0.5815196371994135,
0.6754359269330666,
0.7670656870960783,
0.653416866862045,
0.5281737567081295,
0.3985795104853446,
0.2712146613692562,
0.2759058087446766]
그래프 그리기
plot = sns.lineplot(x=num_clusters, y=sil_score)
plot.set_xlabel("# of clusters");
plot.set_ylabel("Silhouette Score");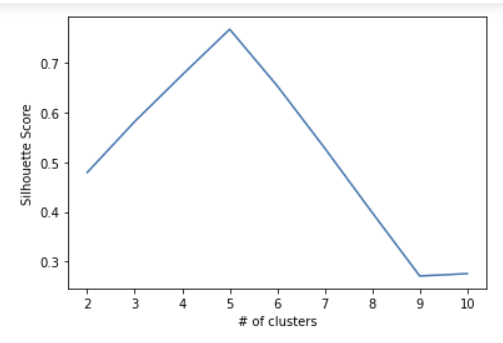
애초에 설정했던 center도 5개였다.! 성공
