목차
연관분석 (Association analysis)
- 효과적인 상품 진열, 잘 팔리는 패키지 상품 개발, 교차판매 전략, 프로모션 기획상품 결정 등에 사용
Run-Test
- 연속적인 관측값을 보고 이것이 통계적으로 유의한지를 검정하는 기법이다.
- H0: 연속적인 관측값이 임의적이다.
- H1: 연속적인 관측값이 임의적이 아니다(즉, 연관이 있다)
두 상품 a, b의 구매패턴이 연관성 있는지 검정하시오.
- 구매패턴: ['b','b','b','b','b','b','a','a','a','a','a','b','b','a','a','a','a','b','b','b']
< 실습 >
run test를 하려면 값을 수치형으로 바꿔야 함
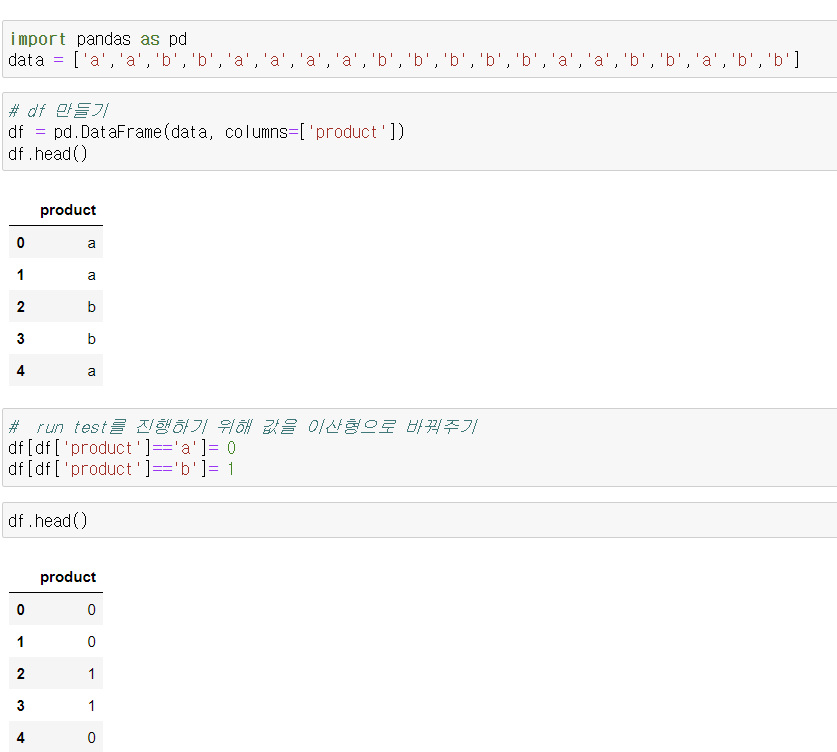
또다른 방법

runstest 모듈 불러오기 / 결과해석
- help 참고

연관규칙분석
- 기업의 DB에서 상품 구매, 서비스 등 사건들 간의 규칙을 발견하기 위해 사용
- 서로 다른 두 아이템의 집합이 얼마나 빈번하게 발생하였는지 관찰
- 사건의 연관규칙을 찾는 방법
- A 후에 B 사건을 실행할 확률
- 소비자 구매패턴, 유튜브 추천 프로그램
- 장바구니분석
- 장바구니에 무엇이 같이 들었는지를 분석
- 서열분석
- A 다음에 B를 산다
- 장바구니분석
연관규칙 분석에 사용되는 척도
A → B
지지도(Support)
- 전체 거래 중, A와 B를 동시에 포함하는 거래의 비율
- 전체 거래 중 해당 아이템이 얼마나 빈번하게 발생하는지 알 수 있다

신뢰도(Confidence)
- A를 포함한 항목 중, A와 B를 동시에 포함하는 거래의 비율
- 조건부확률
- 조건을 포함한 거래 중 장바구니 분석이 얼마나 빈번하게 발생하는지 알 수 있다

향상도(Lift)
- A가 구매되지X B의 구매확률-> A가 구매 O B의 구매확률의 증가비
- A와 B 구매가 서로 관련이 없으면 향상도 1, 양의 상관관계면 1이상, 음의 상관관계면 1이하
- 생성된 규칙이 실제 효용가치 있는지 판별

Apriori
Apriori 에이프라이어리 알고리즘
- 한계
- 가능한 모든 경우의 수를 탐색하여 지지도, 신뢰도, 향상도 높은 규칙을 찾아내는 방식
- 아이템 수가 증가할 수록 소요 시간이 기하급수적으로 증가
- 아이템이 n개 일 때 탐색해야 할 모든 경우의 수: n*(n-1)
- Apriori 알고리즘은 모든 품목집합에 대한 지지도를 전부 계산하는 것이 아니라, 최소 지지도 이상의 빈발항목집합을 찾은 후 그것에 대해서만 연관규칙을 계산
- {A, B}는 {A}, {B}의 초월집합(superset)이라고 하는데, 만일 {A,B}의 지지도가 최소 지지도 이하인 경우, {A,B}의 초월 집합들 예를 들어 {A,B,E}, {A,B,C} 등의 경우도 계산에서 제외해버리기 때문에 효율성이 높아짐
< 실습>
- 패키지 설치(

!pip install mixtend
apriori 함수에 들어갈 transaction data 만들기
from mlxtend.preprocessing import Transaction Encoder
te= TransactionEncoder()
te_result= te.fit(dataset).transform(dataset)
transaction data란?
- 값이 0/1 또는 T/F인 df 형태의 데이터

mlxtend의 apriori 함수
- One-hot형식의 df에서 빈번 항복 집합을 출력하는 함수from mlxtend.frequent_patterns import apriori
apriori(df)
min_support : 최소지지도(default=0.5)

- 길이 추출

- 연관규칙분석 척도

- 이 부분은 아래에서 자세히 해석하도록 하자.
<실습2>
- 데이터 전처리
- 컬럼 -> 마지막 행으로 추가
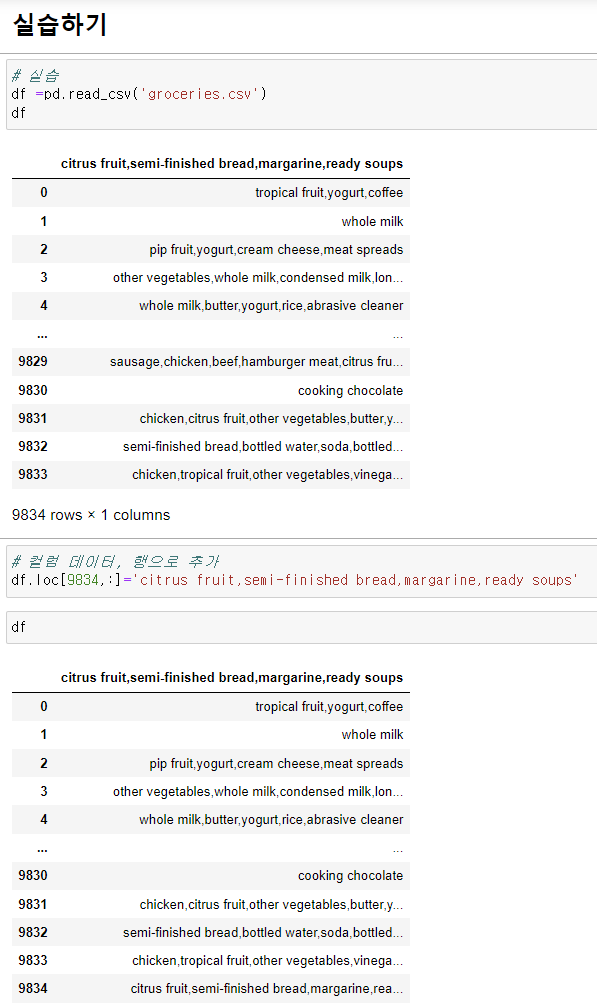
- df로 만든 후, 각 행의 값을 array로 출력

- 필터함수
- 두 개의 인수를 가짐
- 첫 번째: 필터 함수
- None은 기본적으로 True만 반환하는 필터함수
- 두 번째: 필터링할 iterable한 객체

transaction encoder

-apriori 함수 적용하여 빈번항목집합 탐색

- 규칙길이 추출

★ 연관규칙 분석(score, confidence, lift)
- df: support, itemsets 열이 있는 빈번항목집합의 df
- metric : confidence, support, lift
- min_threshold: metric에 지정된 rule의 최솟값

- 길이 추가 > 연관성 높은 것 추출

- 해석

antecedents: 규칙의 선행자(antecedent)
- 어떤 항목 또는 항목 집합이 구성된 규칙의 왼쪽 부분, "yogurt"
consequents: 규칙의 결과자(consequent)
- 어떤 항목 또는 항목 집합이 구성된 규칙의 오른쪽 부분, "whole milk"
antecedent support: 선행자의 지지도(antecedent support)
- 데이터 집합에서 선행자 항목 또는 항목 집합이 발생하는 확률, 예제에서는 0.139502로 "yogurt"의 지지도를 나타냄
consequent support: 결과자의 지지도(consequent support)
- 데이터 집합에서 결과자 항목 또는 항목 집합이 발생하는 확률, 예제에서는 0.255516로 "whole milk"의 지지도를 나타냄
support: 규칙의 지지도(support)
- 데이터 집합에서 선행자와 결과자가 동시에 발생하는 확률, 예제에서는 0.056024로 규칙의 전체 지지도
confidence: 규칙의 신뢰도(confidence)
- 규칙의 지지도와 결과자의 지지도의 비율로 계산
- 선행자가 주어졌을 때 결과자가 발생할 조건부 확률
- 예제에서는 0.401603로 "yogurt"가 주어졌을 때 "whole milk"가 구매될 조건부 확률을 나타냄
lift: 규칙의 향상도(lift)
- 규칙의 신뢰도를 결과자의 지지도로 나눈 것
- 특정 규칙이 발생한 경우 결과자의 발생이 무작위와 비교해 얼마나 "향상"되었는지를 나타냄
- 예제에서는 1.571735로 향상도를 나타냄
leverage: 규칙의 레버리지(leverage)
- 실제로 관찰된 규칙의 발생 빈도와 동일한 데이터 집합에서 선행자와 결과자가 독립적으로 발생하는 것을 기대한 경우의 발생 빈도 간의 차이를 나타냄. 예제에서는 0.020379로 레버리지를 나타냄
conviction: 규칙의 확신(conviction)
- 선행자와 결과자가 독립적으로 발생하는 것을 기대한 경우에 비해 선행자와 결과자의 연관성을 어떻게 평가하는지 나타내며, 값이 1보다 크면 연관성이 높다는 것을 나타냄. 예제에서는 1.244132로 확신을 나타냄
결론
- 이러한 결과를 해석할 때, lift 값이 1보다 크면 선행자와 결과자 간의 양의 상관관계가 있다고 해석할 수 있습니다. confidence 값이 높을수록 선행자가 주어진 경우 결과자가 발생할 가능성이 높다는 것을 나타냅니다.