목차
EDA
- info()

- dtypes
- select_dtypes(include=[np.number])
자료형 선택해서 보여주기
numerical한 경우 / categorical한 경우
train_data.dtypes
train_data.select_dtypes(include=[np.number])
train_data.select_dtypes(exclude=[np.number])

- describe()
기본적으로 numerical data만 나오는데, include="O" 하면 datatype이 object인 것만 나옴

원하는 컬럼만 나오게 하려면, [] 대괄호

4분위값이 아니라, 특정 범위의 값을 알고 싶다면 [] 리스트 안에 넣기

T 전치행렬로 변환도 가능

- value_counts()
normalize하면 더 명확히 비율을 알 수 있음
train_data.Survived.value_counts(normalize=True)
- isna() / fillna()

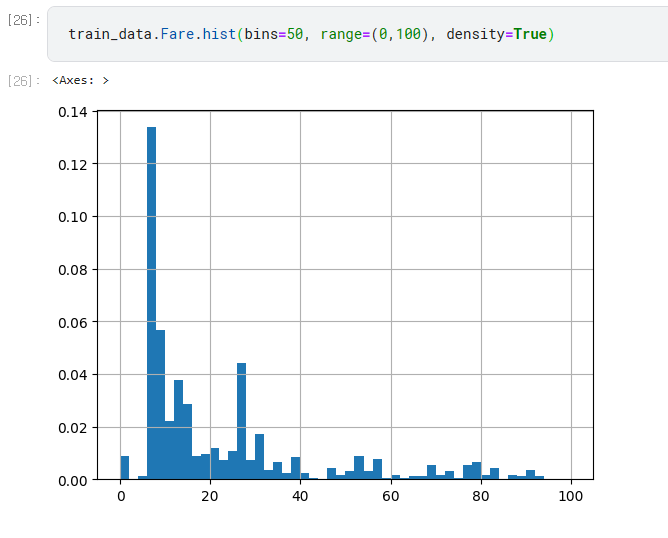
히스토그램
hist()
- bins 히스토그램의 막대 개수 조정
- range() 값의 범위 제한 range=(0, 100)
- density=True 히스토그램 총 면적이 1이 되도록 정규화
- histtype 히스토그램 종류, 기본값은 bar, step
- color


- countplot : categorical data
import matplotlib.pyplot as plt
import seaborn as sns
fig, axes = plt.subplots(3,2, figsize=(10,15))
fig_survived = sns.countplot(x= "Survived", data= train_data, ax= axes[0,0])
fig_survived.set_xlabel("survived people")
fig_survived.set_title("histogram of Survived People")
sns.countplot(x= "Sex", data= train_data, ax= axes[0,1])
sns.countplot(x= "SibSp", data= train_data, ax= axes[1,0])
sns.countplot(x= "Parch", data= train_data, ax= axes[1,1])
sns.countplot(x= "Embarked", data= train_data, ax= axes[2,0])
sns.countplot(x= "Pclass", data= train_data, ax= axes[2,1])
plt.show()
- histplot : numerical data
fig, axes = plt.subplots(1,2, figsize=(10,5))
sns.histplot(x="Fare", data= train_data, kde=True, ax=axes[0])
sns.histplot(x="Age", data= train_data, kde=True, ax=axes[1])
plt.show()
- pairplot
# pairplot
sns.pairplot(data=train_data, vars=["Pclass", "Sex", "SibSp", "Parch", "Age", "Fare","Survived"])
- 자료형 타입에 따라 해석하기 어려운 경우가 많음.
그래서 아래와 같이 barplot을 사용해보자.
- barplot
# barplot
fig, axes = plt.subplots(6,1, figsize=(5, 15))
sns.barplot(x= "Survived", y="Pclass", data= train_data, ax= axes[0])
sns.barplot(x= "Survived", y="Sex", data= train_data, ax= axes[1])
sns.barplot(x= "Survived", y="SibSp", data= train_data, ax= axes[2])
sns.barplot(x= "Survived", y="Parch", data= train_data, ax= axes[3])
sns.barplot(x= "Survived", y="Age", data= train_data, ax= axes[4])
sns.barplot(x= "Survived", y="Fare", data= train_data, ax= axes[5])
plt.show()

상관관계
- drop()
원래 dataframe에서 원하는 컬럼을 삭제하고 싶은 경우에는 drop함수를 쓰고 [] 안에 컬럼명을 적은 후, axis=1을 써준다.
- corr()
데이터 간 상관관계를 나타낸다.
num_data = train_data.select_dtypes(include=[np.number])
num_data_drop = num_data.drop(["PassengerId"], axis=1)
data_corr=num_data_drop.corr()
data_corr
- sns.heatmap
sns.heatmap(data_corr)
타이타닉 캐글 데이터 EDA
'Kaggle' 카테고리의 다른 글
| 4차시 타이타닉 정규표현식 regular expression, label encoding, map함수, as_index, str, replace, pd.cut, sort_values(), astype, mode(), sort_index() (0) | 2024.03.19 |
|---|---|
| 3차시 타이타닉 groupby, facetgrid 클래스 이용해서 데이터시각화, plt.his, sns.barplot, sns.pointplot (1) | 2024.03.18 |
| 1차시 캐글 시작하기 타이타닉 (0) | 2024.03.13 |
| 주파수 사인파 스펙트로그램 EEG 캐글 (0) | 2024.02.13 |
| EEG Pattern LPD GPD LRDA GRDA (0) | 2024.02.13 |