목차
1. groupby
- as_index : groupby 연산의 결과로 생성되는 새로운 DF에서 그룹화 열을 인덱스로 사용할지 여부를 결정
True 그룹화열이 인덱스로 사용
False 그룹화열 인덱스로 사용 X

train_data[['Pclass', 'Survived']].groupby(['Pclass'], as_index=False).mean().sort_values(by="Survived", ascending=True)
train_data[['Pclass', 'Survived']].groupby(['Pclass'], as_index=False).mean().sort_values(by="Survived", ascending=False)
- 마찬가지로 Sex, SibSp, Parch 등 독립변수와 종속변수 Survived를 비교해보기.

2. FacteGrid
Seaborn 라이브러리에서 제공하는 그래프 그리기 위한 클래스이다.
FacetGrid로 특정 기준에 따라 데이터를 분할하여 여러 개의 작은 그래프로 나눠 보여준다.
plt.hist
# FaceGrid
g = sns.FacetGrid(train_data, col="Survived")
g.map(plt.hist, 'Age', bins=20)
row는 col(열)을 row(행)으로 나눈다는 뜻이다. 즉, 아래의 경우 Survived에 따라 열이 나뉘고, Pclass에 따라 행이 나뉘는 것이다.
grid= sns.FacetGrid(train_data, col="Survived", row="Pclass")
grid.map(plt.hist, 'Age')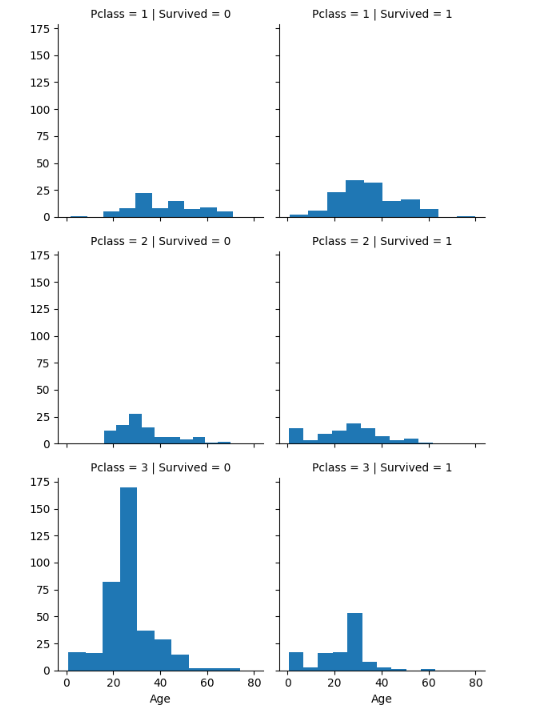
aspect : 가로 세로 비율을 조절해준다. 예를 들어, 1.6이라면 가로:세로 = 1.6:1 이라는 의미
grid= sns.FacetGrid(train_data, col="Survived", row="Pclass", aspect=1.6)
grid.map(plt.hist, 'Age')
sns.pointplot
pointplot은 범주형 변수와 수치형 변수를 시각화한다. 각 범주의 수준별로 수치형 변수의 평균값을 추정해 이를 점으로 표시하여 관계 시각화하는 것이다.
x, y, hue 세 개의 매개변수를 쓴다.
set_xlabels() x축 이름 넣기
tight_layout() 레이아웃 자동조절
add_legend() 범례넣기
grid= sns.FacetGrid(train_data, row="Embarked", aspect=1.6)
grid.map(sns.pointplot, "Pclass", "Survived", "Sex")
grid.set_xlabels("Pclass")
grid.tight_layout()
grid.add_legend()
sns.barplot
g = sns.FacetGrid(train_data, row="Embarked", col="Survived", aspect=1.6)
g.map(sns.barplot, "Sex", "Fare")
alpha : 그래프 투명도. 1이면 완전히 투명, 0이면 불투명
ci : 신뢰구간 confidence interval, 기본값 95%, None 표시안함
g = sns.FacetGrid(train_data, row="Embarked", col="Survived", aspect=1.6)
g.map(sns.barplot, "Sex", "Fare", alpha=0.4, ci=None)