목차
1. 정규표현식 Regular Expression
정규표현식 의미: 문자열에서 패턴을 찾거나 매칭시키기 위해 사용되는 표현 방식이다.
문자열 검색, 대체, 추출 등 다양한 문자열 처리 작업에 유용하게 사용된다.
구성: 일련의 문자 + 메타 문자
. : 어떠한 문자 하나와도 매칭됩니다.
* : 앞의 패턴이 0개 이상의 반복을 의미합니다.
+ : 앞의 패턴이 1개 이상의 반복을 의미합니다.
? : 앞의 패턴이 0개 또는 1개의 반복을 의미합니다.
[] : 대괄호 안에 있는 문자 중 하나와 매칭됩니다.
() : 괄호 안에 있는 패턴을 그룹화하고, 매칭 결과를 추출할 수 있습니다.
\ : 다음에 오는 문자를 이스케이프(escape)하여 특수한 의미를 없앱니다.
train_data['Title']= train_data['Name'].str.extract('([A-Za-z]+)\.', expand=False)
ex) a.b
a로 시작하고 그 뒤에 어떤 문자 하나, 그 다음에 b 가 오는 패턴
axb acb aeb awb
ex) [A-Za-z]
A~Z, a-z 안의 어떤 문자 중 하나와 매칭
a e g h hello world def
ex) A+
A가 1개 이상 반복함
AA AAA AAAA
ex) ([MR])\.
\ escape로 다음에 오는 문자의 특수한 의미를 없앤다.
Mr\. Miss\.
2. str
시리즈 객체에 문자열 메서드를 적용하기 위해서이다.
3. expand=False
결과를 시리즈 형태로 반환
4. pd.crosstab(index, column)
교차표 cross tabulation을 생성하는 기능
교차표는 데이터프레임에서 두 개이상의 변수 간의 관계를 요약하여 표 형태로 나타내는 통계적 도구이다.
범주형 변수들 간의 관계를 파악하고자 할 때 유용하다.
pd.crosstab(train_data['Title'], train_data['Sex'])
5. replace (a, b)
a를 b로 바꿀 때 사용한다.
---> Rare한 것들
['Lady', 'Countess','Capt', 'Col',\
'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona']
---< Mile = Miss 프랑스어로 마드모아젤
---< Ms = Miss
---< Mme = Mrs
---< Master 영어에서 남자 아이나 젊은 남자. 주로 18세 미만 남자 아이. 미혼남자.
train_data['Title'].replace(['Lady', 'Countess','Capt', 'Col',\
'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare', inplace=True)
train_data['Title'].replace('Mlle','Miss', inplace=True)
train_data['Title'].replace('Ms','Miss', inplace=True)
train_data['Title'].replace('Mme','Mrs', inplace=True)train_data['Title'].value_counts(normalize=True)
6. as_index
# 오른쪽 결과
train_data[['Title', 'Survived']].groupby(['Title'], as_index=False).mean()groupby를 통해 만들어진 결과의 인덱스가 그룹의 고유한 인덱스로 설정이 되는데(왼쪽)
as_index=False 를 사용하면그룹의 고유한 값은 컬럼으로 유지되고 새로운 index 0~n이 생성된다. (오른쪽)
7. 라벨 인코딩
★ 수동으로 변경 map 함수
# 라벨 인코딩 --> 수동으로 변경 map 함수
title_mapping = {"Mr":1, "Miss":2, "Mrs":3, "Master":4, "Rare":5}
for dataset in combine:
dataset["Title"] = dataset["Title"].map(title_mapping)

남자는 0, 여자는 1로 라벨인코딩하기
train_data['Sex_num'] = train_data['Sex'].map( {'female': 1, 'male': 0} ).astype(int)
train_data
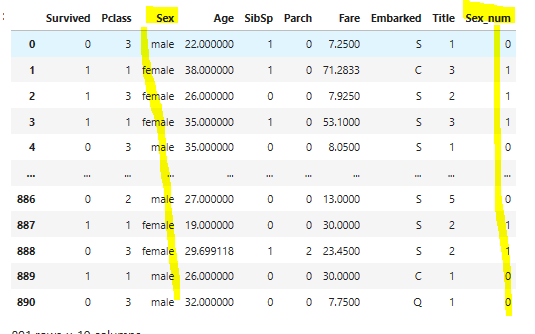
★ loc 함수 써서 구간별로 라벨인코딩
나이구간에 따라 0~4까지 라벨인코딩하기
train_data.loc[train_data['Age']<=16, 'Age'] = 0
train_data.loc[(train_data['Age']>16) & (train_data['Age']<= 32), 'Age'] = 1
train_data.loc[(train_data['Age']>32) & (train_data['Age']<= 48), 'Age'] = 2
train_data.loc[(train_data['Age']>48) & (train_data['Age']<= 64), 'Age'] = 3
train_data.loc[train_data['Age']>64, 'Age'] = 4
8. astype
astype 자료형 바꾸기
astype 뒤에 int, float 쓸 때 ' ' 없이 쓴다!
Age(float ---> int)
train_data.Age=train_data.Age.astype(int)
train_data.Age.info()
9. pd.cut(x, bins) vs pd.qcut()
pd.cut
x 데이터를 몇 개의 bins로 나눈다.
train_data['Age_band']=pd.cut(train_data['Age'], 5)
train_data['Age_band']
train_data[['Age_band', 'Survived']].groupby(['Age_band'], as_index=False).mean()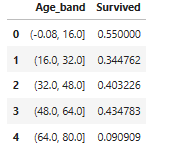
※ qcut vs cut
qcut(), cut() 모두 주어진 데이터를 구간으로 나누는 데 사용.
방식에는 차이가 있다.
pd.cut 주어진 데이터를 지정된 구간 bin으로 나눔. 따라서 데이터의 분포에 따라 각 구간의 데이터 수에는 차이가 있음
pd.qcut
★ 분위수란? 데이터를 순서대로 나열했을 때 일정한 백분율로 데이터를 나누는 지점을 말한다.
대표적으로 사분위수(qartiltes)를 많이 사용한다. 하위25%, 중간값= 하위50%, 하위75%, 100%
pd.qcut은 이렇듯 데이터를 분위수에 따라 나누는데, 각 구간에 포함되는 데이터의 개수가 비슷하도록 분할한다.
train_data['FareBand'] = pd.qcut(train_data['Fare'],4)
train_data[['FareBand', 'Survived']].groupby(['FareBand'], as_index=False).mean().sort_values(by="Survived")
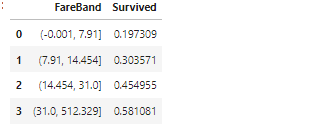
10. sort_values(by= 기준, ascending= 오름차순? 내림차순?)
train_data[['Age_band', 'Survived']].groupby(['Age_band'], as_index=False).mean().sort_values(by="Age_band", ascending=False)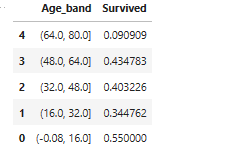
11. sort_index()
인덱스 정렬
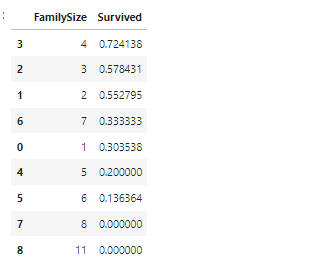
train_data[['FamilySize', 'Survived']].groupby(['FamilySize'], as_index=False).mean().sort_values(by='Survived', ascending=False).sort_index()
12. mode() 최빈값
최빈값들을 리스트로 반환한다. 만약 최빈값이 하나 이상이라면 그 값들을 리스트로 반환한다.
따라서 가장 첫 번째인 값을 구하고자 할 때는 [0]을 이용한다.
train_data.Embarked.mode()0 S
Name: Embarked, dtype: object# 최빈값
train_data.Embarked.mode()[0]'S'
13. 기타 대푯값
대푯값을 구하는 함수를 알아보자.
평균값 (Mean): mean() 데이터의 총합을 데이터의 개수로 나눈 값
중앙값 (Median): median() 데이터를 크기 순으로 나열했을 때 가장 중앙에 위치하는 값
최빈값 (Mode): mode() 데이터에서 가장 자주 등장하는 값
사분위수 (Quartiles): quantile() 데이터를 크기 순으로 나열했을 때 1/4, 2/4, 3/4 위치에 있는 값
표준편차 (Standard Deviation): std() 데이터가 평균으로부터 얼마나 퍼져있는지를 나타내는 값
https://olivia-blackcherry.tistory.com/576
Input validation, validate data, EDA, label encoding, dummy encoding, duplicated(), drop_duplicates(), replace, loc
목차 Input Validation The practice of thoroughly analyzing and double-checking to make sure data is complete, error-free, and high-quality 카레를 만들기 위해 야채를 산다고 했을 때, 살 때만 야채의 신선도를 확인하는 것이
olivia-blackcherry.tistory.com