목차
빅데이터를 가지고 머신러닝 모델로 데이터의 insight를 얻기 위한 일련의 과정을 경험해본다.
1.Data
아래의 두 데이터를 보면, 첫 번째는 완전히 정형화되지 않은 형태의 데이터이고, 두 번째 데이터는 float형태로 변환된 형태의 데이터이다.
data

X
2. Standardize
X를 보면 float형태로 모두 변환되어 있지만 각 컬럼마다 range가 달라서, 머신러닝으로 바로 적용할 경우 효율이 떨어진다. 예를 들면, 시험을 쳤는데 수학은 난이도가 매우 어렵고, 사회는 난이도가 매우 쉬웠다. 결과적으로 두 과목 점수가 똑같이 80점이라 해도 실질적으로 같은 80점 정도의 수준에 있다고 보기 어렵다. 따라서 수학과 사회 난이도를 똑같이 맞춰야 한다.
X도 보면 PayloadMass는 백, 천 단위의 숫자임에 반면, 다른 컬럼 값들은 한 자리 숫자인 것을 볼 수 있다.
모든 컬럼의 range가 동일하도록 standardize(표준화) 작업을 해보자.
transform = preprocessing.StandardScaler()
transform.fit(X)
X= transform.transform(X.astype(float))
XStandardScaler()는 평균이 0이되고, 표준 편차가 1이 되도록 데이터를 조정한다.
fit_transform() 함수는 StandardScaler() 객체를 사용해서 X를 표준화된 형태로 반환한다.
반환할 때 인자로 X.astype(float)를 넣으면 float로 형변환을 한다는 의미다.
또는 fit()함수 이후에 transform()함수를 각각 사용해도 된다.
3. split data
train, test set으로 분리한다.
tran은 훈련 데이터이고, test는 실제 만들어진 모델이 잘 작동하는지 테스트하는 데이터이다.
test_size는 0.2, random_state=2라고 둔다.
random_state는 seed인데, 이것을 어떤 수로라도 정해두면 다음에 이 코드를 실행시켜도 random하게 데이터가 분리되지 않고 매번 같은 테스트, 트레인 데이터가 나온다.
연습을 하는 입장이기에 매번 랜덤한 데이터가 나올 필요가 없기 때문에 random_state를 지정한다.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split( X, Y, test_size=0.2, random_state=2)
print ('Train set:', X_train.shape, Y_train.shape)
print ('Test set:', X_test.shape, Y_test.shape)Train set: (72, 83) (72,)
Test set: (18, 83) (18,)
만약 하이퍼파라미터의 튜닝을 위해 validation data를 두고 싶다면 아래와 같이 3종류로 분리한다.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split( X, Y, test_size=0.2, random_state=2)
X_train, X_val, Y_train, Y_val = train_test_split(X_train, Y_train, test_size=0.2, random_state=2)
print ('Train set:', X_train.shape, Y_train.shape)
print ('Valid set:', X_val.shape, Y_val.shape)
print ('Test set:', X_test.shape, Y_test.shape)Train set: (57, 83) (57,)
Valid set: (15, 83) (15,)
Test set: (18, 83) (18,)
4. 모델 선정
lr=LogisticRegression()
5. GridSearchCV
사이킬런 라이브러리에서 제공하는 하이퍼파라미터 튜닝을 위한 도구이다. 모델의 성능을 최적화하는 하이퍼파라미터를 찾는데 도움을 준다. 작동 원리는 가능한 모든 하이퍼파라미터의 조합을 탐색하여 최적의 조합을 찾는다. 이후에 주어진 하이퍼파라미터 그리드에서 모든 조합에 대해 교차검증(CV: cross validation)을 수행하여 각 조합 성능을 평가한다. 마침내 최적의 하이퍼파라미터 조합을 선택하는 것이다.
높은 cv는 높은 계산 비용(시간 등)이 소요될 수 있다.
가능한 parameter들은 아래와 같고, cv는 10으로 설정했다. 모델은 logisticregression이다.
parameters ={'C':[0.01,0.1,1],
'penalty':['l2'],
'solver':['lbfgs']}
logreg_cv=GridSearchCV(lr, parameters, cv=10)
3번에서 하이퍼파라미터 성능 평가를 위해 별도의 검증데이터를 나눈다고 했었는데, gridsearchCV 같은 경우 별도의 검증 데이터를 나눌 필요가 없다. 학습 단계에서 자동으로 검증 과정을 처리한다.
gridsearchCV는 학습데이터를 여러 fold로 나누고, 각 폴드에 대해 나머지 폴드에서 모델을 학습하고, 현재 폴드에서 모델 성능을 평가한다. 이 과정을 하이퍼파라미터 그리드 각 조합에 대해 반복하고, 최고 점수를 획득한 파라미터를 선택한다.
fit, 학습 시키기
logreg_cv.fit(X_train, Y_train)
best_params_, 최적의 파라미터 선택하기
best_score_ 정확도
print("tuned hpyerparameters :(best parameters) ",logreg_cv.best_params_)
print("accuracy :",logreg_cv.best_score_)tuned hpyerparameters :(best parameters) {'C': 0.01, 'penalty': 'l2', 'solver': 'lbfgs'}
accuracy : 0.8464285714285713
score(), 모델 평가하기
model.score(X_test, y_test)형태로 모델을 평가한다.
# Assuming you have trained your model and named it 'model'
accuracy = logreg_cv.score(X_test, Y_test)
print("Accuracy on test data:", accuracy)Accuracy on test data: 0.8333333333333334
yhat=logreg_cv.predict(X_test)
plot_confusion_matrix(Y_test,yhat)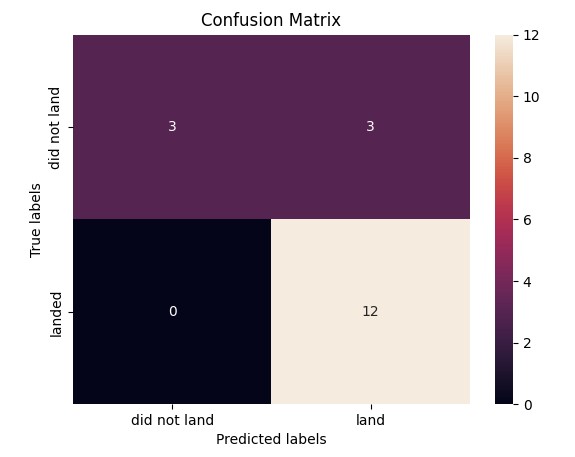
추가 하이퍼파라미터
SVM 하이퍼파라미터
parameters = {'kernel':('linear', 'rbf','poly','rbf', 'sigmoid'),
'C': np.logspace(-3, 3, 5),
'gamma':np.logspace(-3, 3, 5)}
svm = SVC()Decision Tree 하이퍼파라미터
parameters = {'criterion': ['gini', 'entropy'],
'splitter': ['best', 'random'],
'max_depth': [2*n for n in range(1,10)],
'max_features': ['auto', 'sqrt'],
'min_samples_leaf': [1, 2, 4],
'min_samples_split': [2, 5, 10]}
tree = DecisionTreeClassifier()KNN 하이퍼파라미터
parameters = {'n_neighbors': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'algorithm': ['auto', 'ball_tree', 'kd_tree', 'brute'],
'p': [1,2]}
KNN = KNeighborsClassifier()
코딩교육, 데이터교육, 머신러닝 교육, 인공지능 교육, 소프트웨어 교육, 데이터 강의
'머신러닝 > machine learning' 카테고리의 다른 글
| clustering, k-means (1) | 2023.05.18 |
|---|---|
| classification, SVM, support vector machine, kerneling (0) | 2023.05.18 |
| logistic regression, sigmoid, logistic regression vs linear regression, C, optimizer, softmax (0) | 2023.05.18 |
| classification, regression tree (0) | 2023.05.18 |
| classification, decision tree, entropy, 지니계수, information gain (0) | 2023.05.17 |