목차
| 공통목표 | 문제해결 접근방법 | 파이썬 코드 | |
| 통계적 방식 회귀분석 | MSE(평균제곱오차)를 최소화하는 파라미터 찾기 | 정규방정식 | OLS sklearn > LinearRegression() |
| 머신러닝 모델 회귀분석 | 경사하강법 |

경사하강법 Gradient Descent
- 손실함수의 값이 낮아지는 방향으로 독립변수의 값을 바꿔가는 방식이다. 최적의 해법을 찾을 수 있는 최적화 알고리즘으로, 손실함수 값을 최소화하기 위해 파라미터를 반복적으로 조정해나간다.
- Random Initialization 방식으로 임의의 값으로 시작해 한번에 조금씩 함수의 값이 감소하는 방향으로 최솟값에 수렴할 대까지 점진적으로 진행
- 학습률 : 학습 스텝의 크기
- 종속변수 y가 1차원 배열 형태
★ ravel()
y가 2차원 배열인 경우 1차원 배열로 변환해준다.
< 장점 >
1) 복잡한 함수에서 그 해를 쉽게 찾을 수 있음
2) 빅데이터라고 해도 상대적으로 쉽고 바르게 컴퓨터 구현 가능
< 종류 >
1) 배치 경사하강법
- 반복 시 전체 훈련세트를 사용해 가중값을 갱신한다.
- 전체를 계산하기 때문에 계산량이 많아 train에 소요되는 시간이 증가한다.
- 반면 train 시 발생하는 잡음이 적다.
<Python code>
- 선형성 확인
# charges: 의료비용
# x, y 선형성 확인
x= data['age']
y= data['charges']
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(10,5))
plt.scatter(x,y)
plt.xlabel('X')
plt.ylabel('Y')
plt.show()
- Sklearn- LinearRegression()
< 차원 맞추기 >
fit()에 입력되는 x 데이터는 2차원 array여야 한다. reshape으로 차원을 맞춰준다.
from sklearn.linear_model import LinearRegression
x= np.array(x)
x= x.reshape(1338,1)
y= np.array(y)
y= y.reshape(1338, 1)
x.shape, y.shape((1338, 1), (1338, 1)
-scklearn으로 선형회귀모델 만들기
lr = LinearRegression()
lr.fit(x,y)
print("절편", lr.intercept_)
print("회귀계수", lr.coef_)
print("결정계수", lr.score(x,y))절편 [3165.88500606]
회귀계수 [[257.72261867]]
결정계수 0.08940589967885804결정계수가 0.08이라는 말은 해당 모델이 8프로의 설명력을 갖추었다는 것을 의미한다.
-예측값
기존 x값 넣었을 때 해당 모델이 예측하는 y값
y_pred=lr.predict(x)
y_predarray([[ 8062.61476073],
[ 7804.89214207],
[10382.11832874],
...,
[ 7804.89214207],
[ 8578.05999807],
[18886.96474474]])
새로운 x값을 넣었을 때 해당 모델이 예측하는 y값
new_x = [[20], [50]]
y_pred = lr.predict(new_x)
y_predarray([[ 8320.3373794 ],
[16052.01593941]])
- 시각화
plt.figure(figsize=(10,5))
plt.plot(x,y,"b.")
plt.plot(new_x, y_pred, "-r")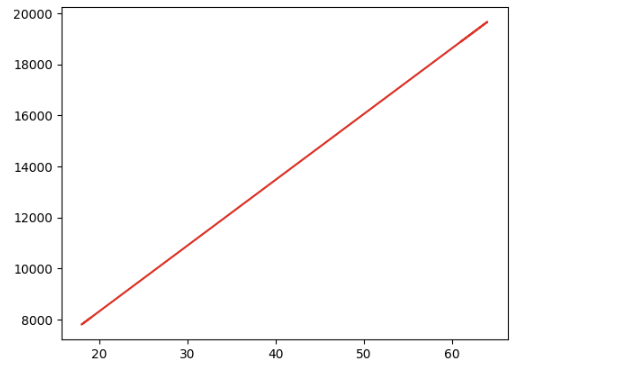
합치면!
plt.figure(figsize= (10,5))
plt.plot(x, y, "b.")
plt.plot(new_x, y_pred, "-r")
plt.xlabel('X')
plt.ylabel('Y')
plt.show()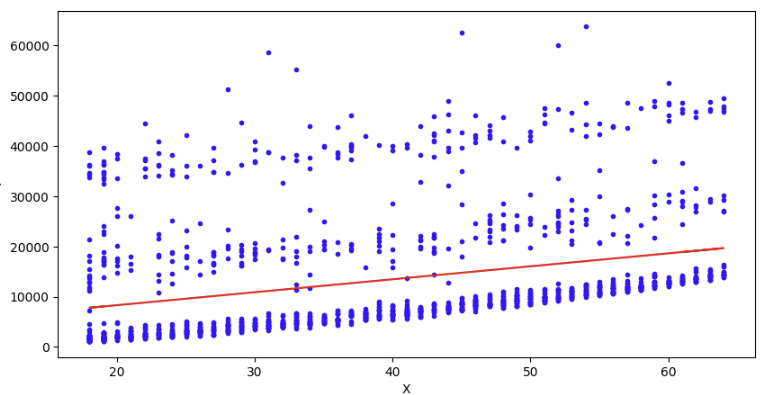
2) 확률적 경사하강법
- 한 개의 샘플데이터를 무작위 선택하고, 그 샘플에 대한 경사를 계산한다.
- 매 반복마다 가중값이 달라지기 때문에 처음에는 잡음이 요동치며 점차 감소한다.
- 지역 최솟값을 건너뛰고 전역최솟값으로 다다를 가능성이 높다.
- 계산 속도가 빠르다.
< Python code >
독립변수 2차원, 종속변수 1차원으로 shape 맞추기
x= np.array(x) # 2차원
x = x.reshape(1338,1)
y= np.array(y) # 1차원
확률적 경사하강법 모델 만들기
SGDRegressor()
from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(max_iter=1000, random_state=45)
sgd_reg.fit(x,y)
새로운 값 넣어 예측값 얻기
x_new=[[20], [50]]
y_pred = sgd_reg.predict(x_new)
y_predarray([14150.68064886, 35976.14123061])
시각화
plt.figure(figsize= (10,5))
plt.plot(x, y, "b.")
plt.plot(x_new, y_pred, "-r")
plt.xlabel('X')
plt.ylabel('Y')
plt.show()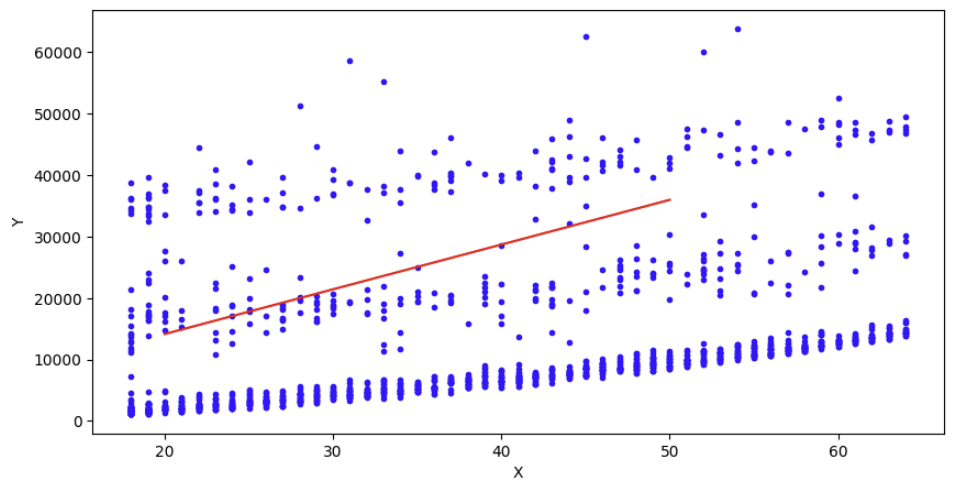
3) 미니배치 경사하강법
- 각 스텝을 반복할 때 임의의 3-50개 관측값으로 경사를 계싼하고 모델의 가중값을 갱신한다.
- 확률적 경사하강법보다 지역 최솟값에서 빠져나오기 어려울 가능성이 있다.
- 확률적 경사하강법보다 오차율이 낮아 최솟값에 더 가까이 도달할 수 있다.
Hold out
데이터 나누기(train/test Split)
# train/ test split
y = data["charges"]
x= data[["age"]]
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x,y, test_size=0.3, random_state=156)
모델 만들고, 회귀계수와 절편 구하기
lr= LinearRegression()
lr.fit(x_train, y_train)
lr.coef_, lr.intercept_(array([277.3952307]), 2842.215527329179)
예측값 구하기
y_pred= lr.predict(x_test)
y_pred[:3]array([18098.95321571, 8112.72491059, 16157.18660082])평가하기
#평가
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
#MAE
mae = mean_absolute_error(y_test, y_pred)
# MSE
mse = mean_squared_error(y_test, y_pred)
# RMSE
rmse = np.sqrt(mse)
#R2 score
r2score= r2_score(y_test, y_pred)
print("MAE:{0:.3f}".format(mae))
print("MSE:{0:.3f}, RMSE: {1:.3f}".format(mse, rmse))
print("R2 Score:{:.3f}".format(r2score))1. MAE (Mean Absolute Error)
실제값과 예측값의 차이를 절댓값으로 변환해 평균한 것
평균 절대값 오차 (실제값-예측값--> 절댓값)의 평균
2. MSE (Mean Squared Error)
실제값과 예측값의 차이를 제곱해 평균한 것
residual error을 합한 것의 평균: 오차제곱(실제값-예측값--> 제곱)의 평균
3. RMSE
MSE 값은 오류의 제곱이므로 실제 오류 평균보다 더 커지는 특성이 있으므로, MSE에 루트를 씌운 것
4. R squared
결정계수. 예측값 variance / 실제값 variance (분산 기반으로 예측성능을 평가한 것.)
데이터의 점들이 얼마나 회귀선과 근접하는지 알려줌. 분산 기반으로 예측 성능을 평가. 1에 가까울 수록 정확도 높음.
교차검증
과적합의 문제를 개선하기 위해 교차검증을 이용하여 다양한 학습과 평가를 시행한다.
별도의 여러 데이터 세트로 구성된 학습 데이터와 검증데이터에서 학습과 평가를 수행한다.
수능 한 번을 치는게 아니라, 일년 동안 모의고사를 여러번 쳐서 그 결과를 합쳐 평균을 내는 것과 같다.
| Data | ||
| Train Data |
Test Data | |
| Train Data | Validation Data | Test Data |
K fold 교차 검증
k개의 데이터 세트(train, validation, test)를 만들어서 k번 데이터 학습, 검증, 평가를 반복적으로 수행한다.

Scroing 함수(cross_val_score_ 사용할 때 유의할 점)
cross_val_score(estimator, x, y, scoring, cv)
- estimator: 평가할 모델 객체
- x: 특성 데이터 (훈련데이터--> xtrain)
- y: 타깃 데이터 (훈련데이터--> ytrain)
- scoring: 평가지표
- cv: 교차검증(기본값:5)
★회귀
default: r2
neg_mean_squared_error
회귀 평가지표를 적용할 때 neg_라는 접두어가 붙은 것을 주의해야 한다. 기본적으로 scoring 함수는 값이 클 수록 평가가 좋게 나온다. 하지만 회귀모델 평가에서는 실제값과 예측값의 오류 차이를 기반으로 하기 때문에, 값이 커지면 나쁜 모델일 확률이 높다. 다라서, -1을 원래 평가점수에 곱해서 음수를 만들어, 작은 오류 값이 더 큰 숫자로 인식하도록 만든다.
# 교차검증 --> scoring: neg_mean_square--> 반환되는 모든 수는 음수
from sklearn.model_selection import cross_val_score
cross_lr = LinearRegression()
neg_mse_score = cross_val_score(cross_lr, x, y, scoring="neg_mean_squared_error", cv=3)
print("3 folds 개별 Negative MSE score: ", np.round(neg_mse_score,2))#rmse 구하기
rmse_score = np.sqrt(-1*neg_mse_score)
avg_rmse = np.mean(rmse_score)
print("3 fold 개별 RMSE score: ", np.round(rmse_score, 2))
print("3 fold 평균 RMSE : {0:.3f}".format(avg_rmse))
★ 분류
default: accuracy
accuracy, precision, recall, f1
분류 평가지표를 적용할 때는 위의 방식이 scoring으로 쓰인다.
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LinearRegression
# 회귀 문제에서 R^2 점수 사용
model = LinearRegression()
scores = cross_val_score(model, X, y, cv=5, scoring='r2')
print(scores)
# 분류 문제에서 정확도 사용
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
model = DecisionTreeClassifier()
scores = cross_val_score(model, iris.data, iris.target, cv=5, scoring='accuracy')
print(scores)
11차시 선형회귀(머신러닝) 총정리, ravel(), 교차분석, scoring, neg_mean_squared_error