1. 데이터셋 설치
!pip install datasets
2. 데이터셋 살펴보기
# 데이터셋 리스트
from datasets import list_datasets
all_datasets = list_datasets()
print(len(all_datasets)) # 몇 개?
print(all_datasets[0]) # 첫 번째 데이터셋
# 데이터셋 로드
from datasets import load_dataset
emotions = load_dataset("emotion")
emotions197878
amirveyseh/acronym_identificationDatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 16000
})
validation: Dataset({
features: ['text', 'label'],
num_rows: 2000
})
test: Dataset({
features: ['text', 'label'],
num_rows: 2000
})
})
# 자세히 더 들여다보기

3. 데이터프레임으로 변환
import pandas as pd
emotions.set_format(type="pandas")
df = emotions["train"][:]
df.head()
# 라벨을 int-> str타입으로 변경
def label_int2str(row):
return emotions["train"].features["label"].int2str(row)
df["label_name"] = df["label"].apply(label_int2str)
4. 클래스 분포 확인
import matplotlib.pyplot as plt
df['label_name'].value_counts(ascending=True).plot.barh()
plt.title("Frequency of Classes")
plt.show()
5. 토큰화
5-1 단어 토큰화
** Text 길이 확인 --> Token 텍스트의 기본 단위
- 입력할 때 token 단위로 입력함
- transformer 모델은 maximum context size 최대 문맥 크기라는 최대 입력 시퀀스 길이가 있음.
- 각 클래스 당 입력 길이를 살펴보고, 텍스트가 모델의 문맥 크기보다 길면 잘라야 하기 때문에 길이를 살펴봐야함
- 최대 문맥 크기 초과: 만약 입력된 텍스트가 너무 길어서 모델이 한 번에 처리할 수 있는 토큰 수를 초과하면, 초과된 부분은 잘리게 됨. 예를 들어, 모델의 문맥 크기가 512 토큰인데 입력 텍스트가 1000 토큰이면, 마지막 488 토큰은 잘리거나 별도로 처리되어야 함
- 이 경우에는 중요한 정보가 손실될 수 있어, 텍스트의 길이를 모델의 문맥 크기에 맞게 조정하는 것이 필요
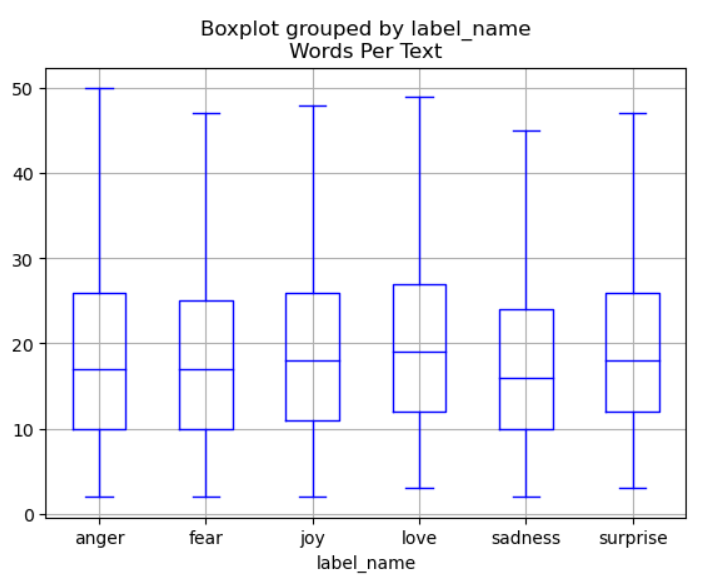
df["Words Per Text"]=df["text"].str.split().apply(len)
df.head()
# 시각화
# showfliers : outliers 표시 여부
df.boxplot("Words Per Text", by ="label_name", grid = True, showfliers=False, color = "blue")
- 단어 단위 분할
- 마침표, 물음표 등이 고려되지 않음
- 철자 오류 또는 곡용(declination, great-greatest-greater) 고려 안됨
- 어휘사전이 큼
- 대안으로 드물게 나타나는 단어는 unknown으로 분류하여 정보를 없애버릴 수 있음
text = "Do you understand?"
tokenized_text = text.split()
print(tokenized_text)['Do', 'you', 'understand?']
5-2 문자 토큰화
- 문자 단위 분할
- 텍스트 구조를 무시하고 전체 문자열을 문자 스트림으로 처리함
- 철자 오류, 희귀한 단어 처리 유용
- 보통 단어 같은 언어구조를 학습하기에는 힘듬
- 시간 오래 걸림
# list()
# 문자 토큰화
text = "Do you understand?"
tokenized_text = list(text)
print(tokenized_text)['D', 'o', ' ', 'y', 'o', 'u', ' ', 'u', 'n', 'd', 'e', 'r', 's', 't', 'a', 'n', 'd', '?']
# 매핑 딕셔너리 만들기
# 문자 -> 정수화 numericalization
# 매핑 딕셔너리 만들기
token2idx = {ch:idx for idx, ch in enumerate(sorted(set(tokenized_text)))}
token2idx{' ': 0,
'?': 1,
'D': 2,
'a': 3,
'd': 4,
'e': 5,
'n': 6,
'o': 7,
'r': 8,
's': 9,
't': 10,
'u': 11,
'y': 12}
# 문자 정수화
# 문자 -> 정수화
# 숫자 식별자로 매핑
input_ids = [token2idx[token] for token in tokenized_text]
print(input_ids)
print(len(input_ids))[2, 7, 0, 12, 7, 11, 0, 11, 6, 4, 5, 8, 9, 10, 3, 6, 4, 1]
18
# 원핫인코딩
# 원핫인코딩
import torch
import torch.nn.functional as F
# 입력값
input_ids = torch.tensor(input_ids) # pytorch tensor로 변환
one_hot_encodings = F.one_hot(input_ids, num_classes=len(token2idx))
# num_classes는 token2idx의 길이를 사용해 각 토큰에 해당하는 고유 인덱스 위치에 1을 주고 나머지는 0으로 채움
one_hot_encodings.shape
5-3 부분단어 토큰화
- 문자 토큰화 + 단어 토큰화 결합
- 드물게 등장하는 단어를 더 작은 단위로 나누면 모델이 복잡한 단어나 철자 오류를 처리하기 용이함
- 입력 길이를 적절한 크기로 유지하기 위해 자주 등장하는 단어는 고유한 항목으로 유지
# AutoTokenizer
from_pretrained() 사전에 학습된 모델 불러오기
from transformers import AutoTokenizer
# 사전 훈련된 모델에 연관된 토크나이저를 빠르게 로드하는 클래스 : AutoTokenizer
# checkpoint 이름 사용해 모델, 가중치, 어휘사전 자동 추출하는 자동 클래스.
# 다양한 모델에 대해 자동으로 올바른 토크나이저 선택해주는 유연한 클래스.
# 특정 모델을 지정하면, 해당 모델에 맞는 적합한 토크나이저를 로드함
model_ckpt = "distilbert-base-uncased"
# model_ckpt = model checkpoint : 모델 학습 중간에 저장된 상태, 모델의 가중치(weights), 학습상태, optimizer parameter 등 저장
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
# from_pretrained() : 허브의 모델ID나 로컬 파일 경로와 함께 호출하기
# 어휘사전 크기
tokenizer.vocab_size
tokenizer.model_max_length
encoded_text = tokenizer(text)
encoded_text30522512{'input_ids': [101, 2079, 2017, 3305, 1029, 102], 'attention_mask': [1, 1, 1, 1, 1, 1]}
# 숫자를 토큰으로 바꾸기
tokens= tokenizer.convert_ids_to_tokens(encoded_text.input_ids)
tokens
# cls : 101, sep:102
# cls- classification 문장 시작을 나타내는 토큰
# sep- seperation 문장 또는 문단 간 구분
# #은 공백 아님['[CLS]', 'do', 'you', 'understand', '?', '[SEP]']
tokenizer.convert_tokens_to_string(tokens)'[CLS] do you understand? [SEP]'
허깅페이스, 트랜스포머, 자연어처리, 데이터셋로드, 문자, 단어, 토큰화, AutoTokenizer
'머신러닝 > 자연어처리' 카테고리의 다른 글
| 자연어처리, 트랜스포머, 허깅페이스 토큰 로그인 모델 가져오기 저장하기, 미세튜닝, AutoTokenizer, transformer, confusionmatrixdisplay, 혼동행렬 시각화, trainer, trainingArguments (0) | 2024.08.25 |
|---|---|
| 자연어처리, 트랜스포머, 구글 코랩 GPU 사용 방법, T4GPU TPUv2, cls토큰 (0) | 2024.08.22 |
| 트랜스포머, 자연어처리, pipeline, 감정분류, 개체명인식, 질문답변, 요약, 생성 (0) | 2024.08.22 |
| 차원감소(dimensionality reduction), SVD (0) | 2022.07.29 |
| 점별 상호정보량 Pointwise Mutual information(PMI) (0) | 2022.07.29 |