1. ModelName<For>Task
트랜스포머는 아키텍처와 작업마다 전용 클래스를 제공한다.
ModelName + For + Task 형식은 허깅페이스의 transformers 라이브러리에서 제공하는 특정한 Task에 맞춰 설계된 모델 클래스이다. 모델이름 + 작업이름을 조합한 클래스명이다. 각기 다른 자연어처리NLP 작업에 특화된 구조를 가지고 있어, 사용자는 각 작업에 적합한 모델을 쉽게 불러와서 사용할 수 있다.
1) GPT2ForCausalLM
gpt2 모델을 casual language modeling 작업에 맞춰 사용한다.
casual language model이란 다음에 올 단어를 예측하는 언어 생성 작업이다.
from transformers import GPT2ForCausalLM
model = GPT2ForCausalLM.from_pretrained("gpt2")
2) BERTForSequenceClassification
BERT 모델을 Sequence Classification 작업에 맞춰 사용한다.
텍스트 분류작업 예컨데 감정분석이나 뉴스 기사 분류 등에서 사용한다.
from transformers import BERTForSequenceClassification
model = BERTForSequenceClassification.from_pretrained("bert-base-uncased")
3) T5ForConditionalGeneration
T5 모델을 Conditional Generation 작업에 맞춰 사용한다.
기계 번역, 텍스트 요약 등 입력된 텍스트를 조건으로 새로운 텍스트를 생성하는 작업이다.
from transformers import T5ForConditionalGeneration
model = T5ForConditionalGeneration.from_pretrained("t5-base")
2. 자주 사용되는 작업 종류
트랜스포머 라이브러리에서는 이러한 형식을 통해 다양한 사전 학습된 모델을 쉽게 불러와 각기 다른 자연어 처리 Task에 사용할 수 있다.
- CausalLM: Causal Language Modeling, 다음 단어 예측.
- MaskedLM: Masked Language Modeling, 마스킹된 단어 예측.
- SequenceClassification: 텍스트 시퀀스를 분류.
- TokenClassification: 각 단어(토큰)를 분류.
- QuestionAnswering: 주어진 질문에 대한 답을 찾는 작업.
- MultipleChoice: 여러 선택지 중 하나를 선택하는 작업.
- ConditionalGeneration: 입력 텍스트를 기반으로 새로운 텍스트를 생성.
3. 그리디 서치 디코딩 방법
연속적인 모델 출력에서 이산적인 토큰을 얻느느 가장 간단한 디코딩 방법
반복문을 통해 확률이 가장 높은 토큰을 greedily하게 선택하는 것.
다만 그리디 서치 알고리즘은 반복적인 출력 시퀀스를 생성하는 경향 때문에 정확한 사실에 근거한 내용에 있어서는 부적절함.
아래 예시>>
총 8번의 반복으로 8개의 단어를 생성하는데,
각 반복당 가장 높은 확률을 가진 후보 5개를 골라줌
# 딥러닝 모델 만들고 학습 및 추론
import torch
# AutoTokenizer : 지정된 모델의 사전 학습된 토크나이저를 자동으로 불러옴
from transformers import AutoTokenizer, AutoModelForCausalLM
device = "cuda" if torch.cuda.is_available() else "cpu"
model_name = "gpt2-xl"
tokenizer = AutoTokenizer.from_pretrained(model_name)
# gpt-2 xl 모델을 사전 학습된 가중치와 함께 불러옴
model = AutoModelForCausalLM.from_pretrained(model_name).to(device)
Toknizer()
input_ids와 attention_mask 있음
import pandas as pd
input_txt = "Studying hard is"
input = tokenizer(input_txt)
input{'input_ids': [13007, 1112, 1327, 318], 'attention_mask': [1, 1, 1, 1]}
return_tensors= "pt"
Pytorch 모델의 입력 데이터로 넣기 위해 torch.Tensor 형식으로 바꿈
import pandas as pd
input_txt = "Studying hard is"
# Pytorch 모델의 입력 데이터로 넣기 위해 torch.Tensor 텐서형식으로 바꿈
input_ids = tokenizer(input_txt, return_tensors="pt")["input_ids"].to(device)
input_ids
가. CasuallLM 사용
반복문 : 다음에 올 단어 예측하기
iterations=[] # 텍스트 선택지을 저장할 리스트
n_steps = 8 # 몇 번의 반복을 수행할지
choices_per_step= 5 # 각 반복에서 모델이 생성할 텍스트 선택지의 수
with torch.no_grad():
for _ in range(n_steps):
iteration = dict()
iteration["Input"] = tokenizer.decode(input_ids[0])
output= model(input_ids=input_ids)
next_token_logits = output.logits[0,-1,:]
next_token_probs = torch.softmax(next_token_logits, dim=-1)
sorted_ids = torch.argsort(next_token_probs, dim=-1, descending=True)
for choice_idx in range(choices_per_step):
token_id = sorted_ids[choice_idx]
token_prob = next_token_probs[token_id].cpu().numpy()
token_choice = (
f"{tokenizer.decode(token_id)} ({100*token_prob: .2f}%)"
)
iteration[f"Choice {choice_idx+1}"] = token_choice
input_ids = torch.cat([input_ids, sorted_ids[None, 0, None]], dim=-1)
iterations.append(iteration)
pd.DataFrame(iterations)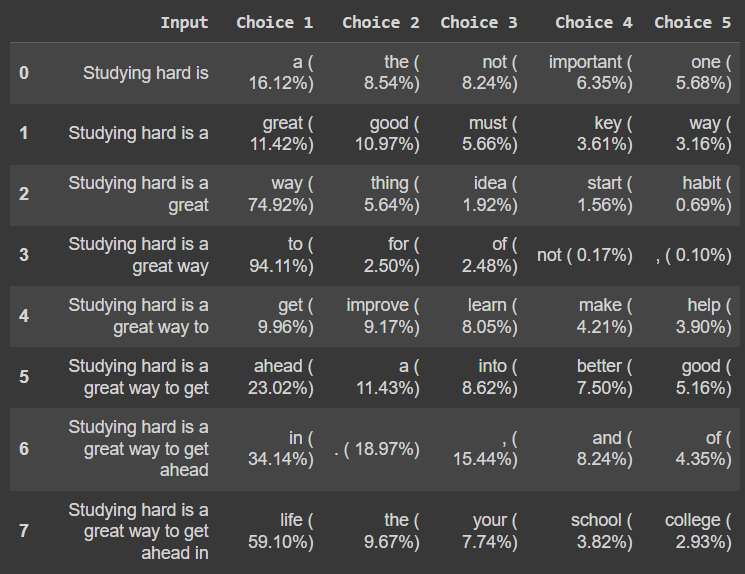
0) decode
숫자 -> 토큰으로 디코드
tokenizer.decode(input_ids[0])
1) torch.no_grad()
gradient 계산 비활성화 - 모델 추론 과정에서 gradient 계산 필요없는 상황에서 메모리 사용 줄이고 계산 속도 높임
with torch.no_grad():
for _ in range(n_steps):
iteration = dict()
iteration["Input"] = tokenizer.decode(input_ids[0])
2) logit
output 객체에서 가장 중요한 부분으로 모델이 생성한 확률분포이다. gpt2 모델이 가지고 있는 어휘 사전 중, 각 토큰별로 입력한text 다음에 해당 단어가 나올 확률 나열
# 모델의 객체 출력 output
output= model(input_ids=input_ids)
print(output)
# logit : 객체에서 가장 중요한 부분
# 모델이 생성한 확률 분포로, 각 토큰이 다음에 나올 단어일 확률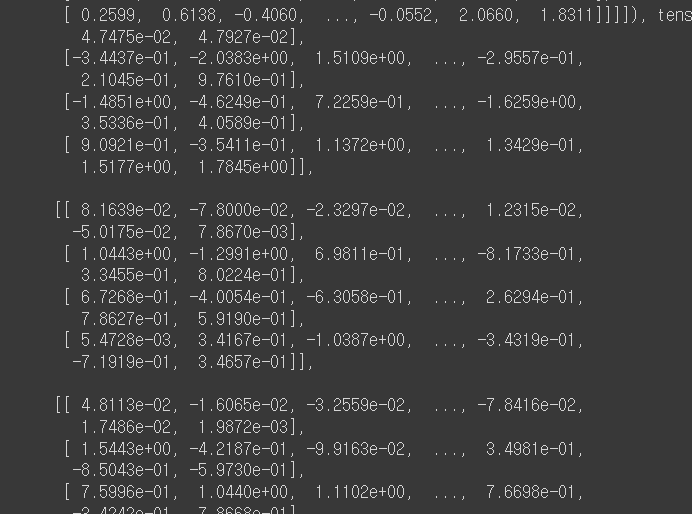
3) logits.shape
1: 배치크기, 2: sequence_length 입력 텍스트의 토큰 개수, 3: vocab_size : 모델이 가진 어휘의 크기
print(output.logits.shape)
torch.Size([1, 4, 50257])
4) vocab_size
logit은 각 토큰 위치마다 다음 토큰이 될 확률 분포를 제공함
logit의 마지막 차원 vocab_size에서 가장 높은 값을 가지는 인덱스가, 해당 모델이 다음 토큰이 될 확률이 높다고 예측한 단어임
next_token_logit = output.logits[0,-1,:]
next_token_logittensor([ 0.3211, 0.4498, -4.1960, ..., -7.3613, -5.3856, -1.3052])next_token_probs = torch.softmax(next_token_logits, dim=-1)
next_token_probstensor([2.1529e-06, 8.5254e-07, 7.2870e-09, ..., 4.1026e-09, 5.4505e-10,
1.1215e-06])argsort : 텐서의 값을 기준으로 정렬된 인덱스 반환 / 오름차순
dim =-1 마지막 차원을 기준으로 정렬하겠다는 의미(vocabulary어휘크기)
sorted_ids = torch.argsort(next_token_probs, dim=-1)
sorted_idstensor([30905, 202, 185, ..., 534, 262, 1204])
나. generate 함수 사용
< 짧은 문장 >
input_ids = tokenizer(input_txt, return_tensors="pt")["input_ids"].to(device)
output = model.generate(input_ids, max_new_tokens=n_steps, do_sample=True)
print(tokenizer.decode(output[0]))Studying hard is a great way to get ahead in life
< 긴 문장 >
max_length=128
input_txt = """
On August 26, 2024, researchers announced a breakthrough \
in developing disease and climate-resistant wheat varieties. \
These new wheat strains could help improve food security \
for over 1.5 billion people in the Global South, \
offering hope to vulnerable populations facing climate challenges.
"""
input_ids = tokenizer(input_txt, return_tensors="pt")["input_ids"].to(device)
output_greedy = model.generate(input_ids, max_length=max_length, do_sample=False)
print(tokenizer.decode(output_greedy[0]))
>>
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
On August 26, 2024, researchers announced a breakthrough in developing disease and climate-resistant wheat varieties. These new wheat strains could help improve food security for over 1.5 billion people in the Global South, offering hope to vulnerable populations facing climate challenges.
The research was led by the University of California, Davis, and the International Maize and Wheat Improvement Center (CIMMYT) in Mexico.
"We are excited to see the potential of this new technology," said CIMMYT Director Dr. Carlos Pineda. "We are confident that this technology will help us to address the challenges of climate