목차
1. 라이브러리
import numpy as np
import pandas as pd
import matplotlib as plt
import pickle
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn import metrics
from xgboost import XGBClassifier
from xgboost import plot_importance
2. 데이터

3. feature engineering
airline_data_dummies = pd.get_dummies(airline_data, columns=['satisfaction','Customer Type','Type of Travel','Class'])
4. data split
y = airline_data_dummies['satisfaction_satisfied']
X = airline_data_dummies.drop(['satisfaction_satisfied','satisfaction_dissatisfied'], axis = 1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
5. xgboost 모델 만들기
xgb = XGBClassifier(objective='binary:logistic', random_state=0)
6. GridSearchCV 교차검정으로 최적의 하이퍼파라미터 구하기
cv_params = {'max_depth': [4, 6],
'min_child_weight': [3, 5],
'learning_rate': [0.1, 0.2, 0.3],
'n_estimators': [5,10,15],
'subsample': [0.7],
'colsample_bytree': [0.7]
}
scoring = {'accuracy', 'precision', 'recall', 'f1'}
xgb_cv = GridSearchCV(xgb,
cv_params,
scoring = scoring,
cv = 5,
refit = 'f1'
)
7. 학습시키기
xgb_cv = xgb_cv.fit(X_train, y_train)
8. 최적의 파라미터
xgb_cv.best_params_{'colsample_bytree': 0.7, 'learning_rate': 0.3, 'max_depth': 6, 'min_child_weight': 3, 'n_estimators': 15, 'subsample': 0.7}
9. 피클
pickle.dump(xgb_cv, open('xgb_cv.sav', 'wb'))
10. 평가
1) 예상값
y_pred = xgb_cv.predict(X_test)
2) 점수
ac_score = metrics.accuracy_score(y_test, y_pred)
print('accuracy score:', ac_score)
pc_score = metrics.precision_score(y_test, y_pred)
print('precision score:', pc_score)
rc_score = metrics.recall_score(y_test, y_pred)
print('recall score:', rc_score)
f1_score = metrics.f1_score(y_test, y_pred)
print('f1 score:', f1_score)accuracy score: 0.9340314136125655
precision score: 0.9465036952814099
recall score: 0.9327170868347339
f1 score: 0.9395598194130925
3) 혼동행렬
cm = metrics.confusion_matrix(y_test, y_pred)
disp = metrics.ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=xgb_cv.classes_)
disp.plot()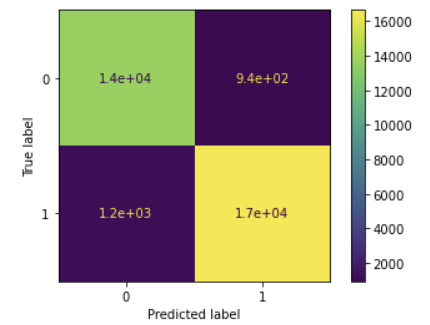
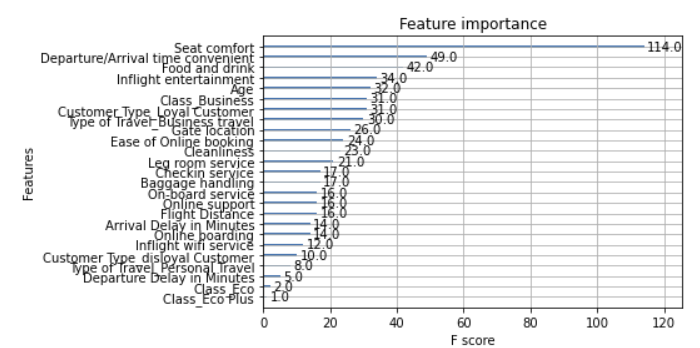
11. 피처 중요도
plot_importance(xgb_cv.best_estimator_)